Home › Forums › Fórum Reconhecimento de Textos com OCR e Python › Reconhecimento de texto em imagens com muitos contornos
- This topic has 1 reply, 2 voices, and was last updated 4 years, 9 months ago by
 Gabriel Alves.
Gabriel Alves.
-
AuthorPosts
-
22 de setembro de 2021 at 10:35 #30895
Olá, tudo bem?
Estou acompanhando as aulas e em paralelo estou desenvolvendo um projeto de reconhecimento de texto em imagens de componentes industriais que tem muitos contornos. Ex.:
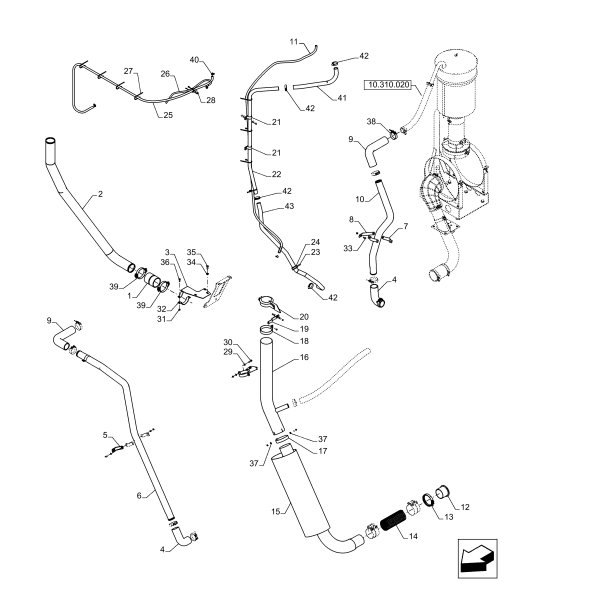
Eu consegui um bom avanço no reconhecimento utilizando algumas técnicas de remoção dos contornos no pré-processamento e, em seguida, realizando o reconhecimento direto com o Tesseract e filtro pela confiança da detecção. Porém, em alguns casos os contornos nos textos são removidos, o que diminui a assertividade ou o não reconhecimento em alguns casos:
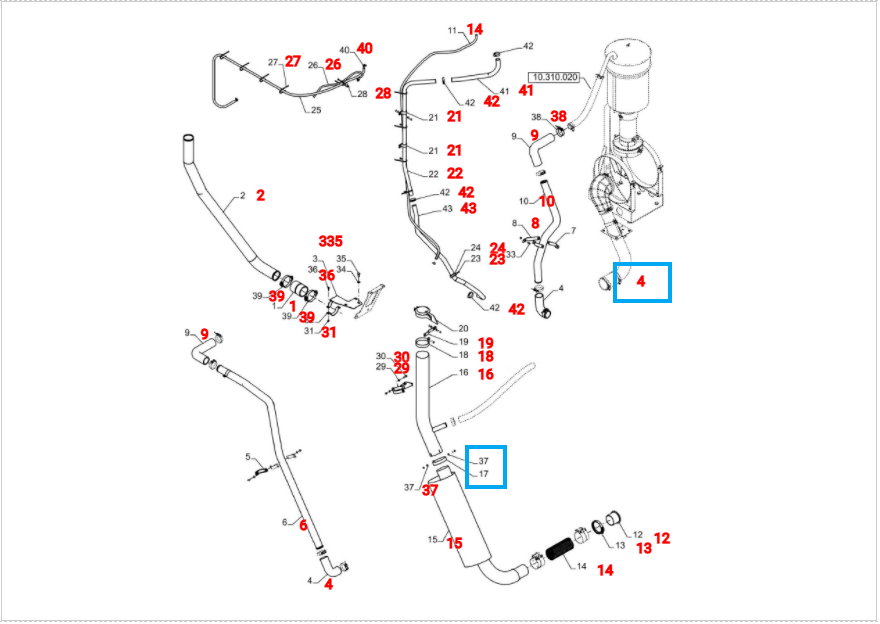
O professor teria alguma sugestão de como melhorar esse processo? Estou na metade do curso e vi apenas algumas técnicas. Tentei aplicar a rede neural EAST no processo (sem remover os contornos) mas não consegui nenhuma melhora ainda.
Esse é o passo-a-passo executado atualmente:
- Conversão para escala de cinza
- Threshold Normal (127, 255, Binário Inv)
- Remoção de contornos (cv2.findContours – triângulos, retângulos e perímetros conforme a área)
- Remoção de linhas horizontais (cv2.morphologyEx)
- Remoção de linhas verticais (cv2.morphologyEx)
- Reconhecimento de texto (Tesseract)
- Filtro de confiança do reconhecimento
Desde já agradeço,
Abraços,
27 de setembro de 2021 at 01:15 #30928Olá Danillo!
Talvez a essa altura você já esteja em outra parte do curso e tenha verificado as outras técnicas que tem disponível, caso não tenha então eu recomendaria antes isso.
Mas caso já tenha visto ou se quiser tentar melhorar o resultado antes disso então eu sugiro que use o resize() para aumentar o tamanho da imagem para pelo menos 150% ou 200% do tamanho da imagem original, basta alterar os parâmetros fx e fy para indicar o fator de escala desejado (nesse exemplo seria 1.5 ou 2.0, respectivamente). Isso é comentado nas aulas sobre pré-processamento, sugiro consultar a aula específica sobre Redimensionamento caso tenha dúvidas sobre como implementar. Você pode realizar esse redimensionamento logo antes de fazer o threshold.
Sobre a tentativa com o EAST: como é necessário redimensionar a imagem para um tamanho padrão (ex: 320×320) pode acontecer de na hora do redimensionamento apagar alguns textos, ou deixando ele indetectável pois a imagem ficou muito menor do que era antes e assim vários detalhes são perdidos, portanto o EAST não vai ter como detectar certos textos. Aliás, esse é o comportamento esperado já que sua imagem é proporcionalmente bem grande em comparação com o texto, então veja que os números aparecem bem pequenos nela. Para tentar resolver isso você pode aumentar o tamanho da imagem fornecida à rede, que por padrão deixamos 320 x 320, mas você pode ir testando com tamanhos maiores tipo pelo menos o dobro ou o triplo desse tamanho padrão (lembrando que esse tamanho da imagem deve ser multiplo de 32), sugiro você ir testando esses tamanhos.
-
This reply was modified 4 years, 9 months ago by Gabriel Alves.
-
AuthorPosts
- You must be logged in to reply to this topic.