
Todos aqueles que andam já há algum tempo pelo mundo da inteligência artificial conhecem a história: as redes neurais foram inventadas lá pela década de 1950, mas foram deixadas de lado durante décadas porque a baixa capacidade computacional fazia com que suas aplicações fossem muito limitadas. Isso mudou no início da década de 1990, quando o avanço tecnológico em hardware finalmente alcançou o ponto em que o conceito das redes neurais passou a ter valor prático.
Assim que as redes neurais começaram a ser exploradas por sua capacidade de resolver problemas, também ficou evidente que sua forma mais básica, a clássica rede neural profunda, não atendia a todas as necessidades. Os pesquisadores da área começaram então a desenvolver novas ideias, baseadas tanto em novos tipos de neurônios quanto em estruturas mais complexas.
Atualmente, entre as redes neurais mais amplamente utilizadas estão as profundas, as convolucionais, as recorrentes, os autoencoders e as generativas. Mas o universo de possibilidades é amplo, e várias outras arquiteturas especializadas em tarefas específicas vem sendo bem estabelecidas.
Neste artigo, apresentamos os principais tipos de redes neurais disponíveis ao desenvolvedor em inteligência artificial. Começamos com um quadro geral que serve de resumo ao tópico, e depois explicitamos os tipos, suas principais características e aplicações.
Este artigo foi inspirado em https://www.asimovinstitute.org/neural-network-zoo/. Todas as figuras foram obtidas ou adaptadas desta fonte.
Perceptron (P), Feed Forward Network (FFN), Radial Basis Network (RBF)

São o tipo mais básico, onde a informação de entrada flui em sequência linear até a saída. Em cada neurônio ocorre uma operação matemática linear do tipo Wx + b, onde x é o valor do dado de entrada, e W e b são os parâmetros peso e bias do neurônio. O resultado dessas operações pode passar por uma função de ativação antes de passar para a camada adiante; no caso específico de funções de ativação com base radial (aquelas que determinam a distância do resultado a um ponto de origem), por questão meramente histórica, a rede correspondente é chamada de rede de base radial. As conexões entre os neurônios representam a passagem de informação de um neurônio para o próximo. Um neurônio que recebe mais de uma conexão de entrada soma estes valores antes de aplicar a equação linear pela qual é responsável. Esta rede neural pode ter várias camadas escondidas entre a camada de entrada e a de saída, por isso também costuma ser chamada de rede neural profunda.
FFNs são capazes de modelar vários problemas onde os dados de entrada têm um impacto atemporal nos dados de saída. Um exemplo é usar informações de um exame de sangue para determinar a presença de uma doença.
Recurrent Neural Network (RNN)

Além dos dados da camada anterior, os neurônios escondidos da rede neural recorrente também recebem o resultado da operação matemática que eles mesmos realizaram no período temporal anterior. Dessa forma, as RNNs consideram uma dependência temporal entre os dados de entrada.
Por terem essa característica, essas redes podem modelar problemas com característica temporal, como por exemplo a previsão do tempo dado o histórico climático em uma janela do passado.
Long short-term memory (LSTM)

As redes do tipo long short-term memory (memória de curto-prazo longa) foram desenvolvidas para resolver um problema comum nas redes neurais recorrentes, os gradientes que explodem ou desaparecem, que fazem com que a relação temporal que a rede deve aprender se perca com o tempo. Os neurônios das redes LSTM conseguem isso mantendo uma célula exclusiva para o armazenamento e fluxo da memória, além de portões do tipo entrada, saída e esquecimento, que controlam esse fluxo.
As LSTMs são consideradas evoluções da RNNs, estendendo seu campo de aplicação para, por exemplo, serem capazes de compor textos com coerência semântica e gramatical, onde as palavras anteriores devem manter um grau de relação com as palavras posteriores.
Gated recurrent network (GRU)

As redes neurais com unidades recorrentes com portão são uma variação das LSTMs. O portão de entrada e saída é substituído por um portão de atualização, que é responsável por controlar quanto de informação reter e quanto atualizar. No lugar do portão de esquecimento temos um portão de reset, que funciona de forma análoga mas cuja localização na estrutura é diferente.
As GRUs costumam ter aplicação similar às das LSTMs, mas são mais rápidas e fáceis de treinar. Entretanto, seu desempenho pode ser um pouco menos expressivo.
Auto-encoder (AE)

Os auto-encoders são projetados para representar a informação de entrada em um espaço dimensional menor. Por isso, a camada escondida central dessa rede, que representa esse espaço, deve ter menos neurônios que a camada de entrada. A camada de saída é uma cópia da informação de entrada, de forma que, durante o treinamento, os auto-encoders aprendem a representar a informação original em menos espaço, mas com informação suficiente para reconstruir os dados originais. A primeira metade da rede, que comprime a informação, é chamada de encoder, e a segunda de decoder.
Os auto-encoders podem ser usados tanto para compactar dados para armazenamento e/ou transmissão, quanto para que representar os dados em forma reduzida para que, por exemplo, outra rede neural especializada em uma tarefa específica possa utilizá-los.
Variational auto-encoder (VAE)

O auto-encoder variacional é similar ao auto-encoder apresentado acima, com a diferença de que sua tarefa não é representar os dados originais em um espaço dimensional compactado, mas sim como distribuições probabilísticas. Como essa rede também é treinada para reconstruir os dados originais, essas distribuições costumam ser boas formas de representar a natureza das variáveis de entrada.
Por essas características, os VAEs são utilizados para realizar o treinamento e a inferência em problemas de natureza probabilística.
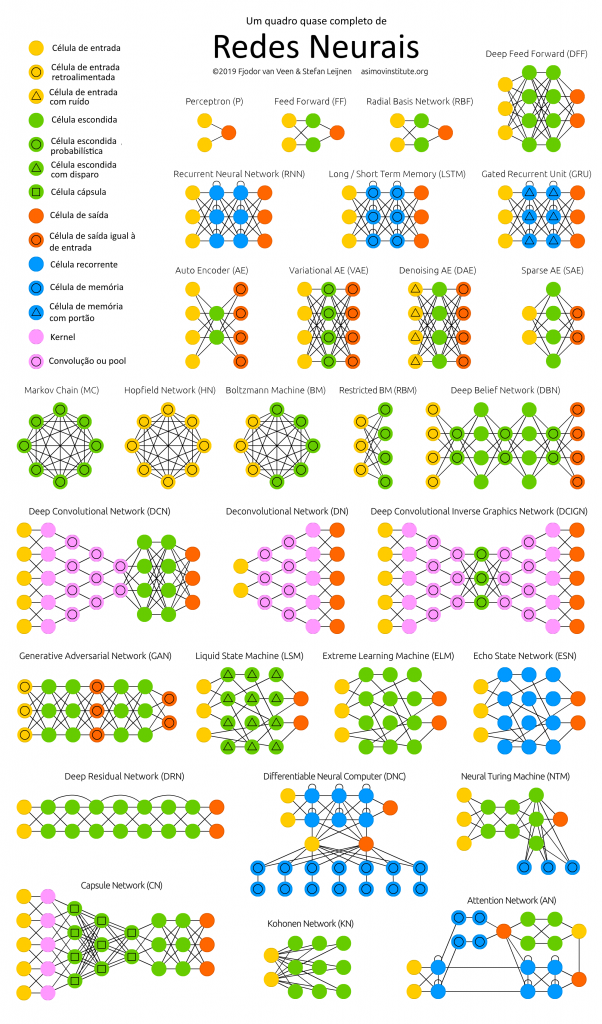
Denoising auto-encoder (DAE)
São auto-encoders cujos dados de entrada são os dados originais adicionados de um ruído. Dessa forma, a rede aprende a capturar informações de uma perspectiva mais ampla, já que em uma escala menor, os dados vão sempre apresentar um ruído de natureza inconstante.
Uma aplicação óbvia dos DAE é limpar dados que contêm ruído por natureza, como por exemplo aumentar a resolução de vídeos antigos.
Sparse auto-encoder (SAE)

O auto-encoder esparso faz o oposto que o auto-encoder tradicional. Ao invés de representar os dados originais em um espaço dimensional menor, ele o faz em um espaço dimensional maior.
O objetivo de SAEs é descobrir novos features menores eventualmente contidos no dataset original mas escondidos nas inter-relações entre os features presentes.
Markov chain (MC)
Apesar de nem sempre serem consideradas redes neurais, as cadeias de Markov podem ser representadas de forma similar, e são precursoras de outras redes. O objetivo das cadeias de Markov é responder a uma pergunta do tipo: dada a presença de um dado em determinado nodo, qual a probabilidade de este dado passar para outro nodo? As cadeias de Markov não contêm memória, de forma que o estado seguinte depende exclusivamente do estado atual, e não de seus antecessores.
Cadeias de Markov são utilizadas, por exemplo, para representar a probabilidade de mutação de um aminoácido durante a evolução, o que é muito importante na área de biologia evolutiva para determinar o grau de parentesco entre as espécies.
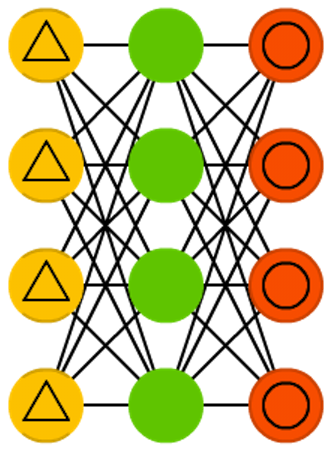
Hopfield network (HN)

A rede de Hopfield tem estrutura similar às cadeias de Markov, mas seu funcionamento é diferente. Primeiro, todos os neurônios são conectados entre si, o que não é requisito na estrutura anterior. Segundo, os neurônios têm todas as funções das camadas de uma rede neural, funcionando como entrada no início, camada escondida durante o treinamento, e saída ao final. A rede é treinada para que seu estado convirja para um estado estável de interesse.
Devido à sua característica prática, ela também é chamada de memória associativa, já que é capaz de se “lembrar” do estado de interesse recebendo como entrada um estado similar. Assim, ela pode ser usada para reconstruir informações completas quando, por exemplo, apenas metade da informação está disponível.
Boltzmann machine (BM)

A máquina de Boltzmann é similar às HNs, com a diferença de que alguns neurônios são explicitamente designados como de entrada (se tornando de saída ao final do treinamento), e outros como escondidos, o que lhe permite usar mais informação que aquela de entrada para atingir um estado estável.
BMs podem ser usadas por exemplo para regular o piloto automático de um avião, onde os dados de entrada são os sinais de vários sensores. Perturbações ambientais são captadas por esses sensores, o que deve provocar ajustes nas partes mecânicas da aeronave para que ela atinja um novo estado de equilíbrio.
Restricted Boltzmann machine (RBM)

A máquina de Boltzman restrita é uma forma não-circular da BM, onde não há inter-conexões entre os neurônios de entrada ou entre os neurônios escondidos. A principal vantagem vem no treinamento, já que elas podem ser treinadas de forma similar a uma FFN.
As aplicações são as mesmas que aquelas das BMs, mas as RBMs costumam ser mais usadas por essa natureza restrita.
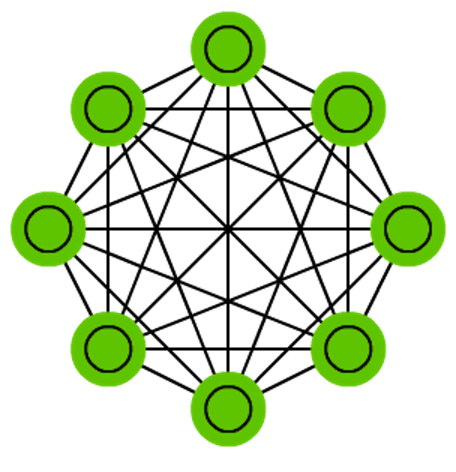
Deep belief network (DBN)
A rede de crença profunda é uma forma empilhada das RBMs ou de VAEs, onde cada camada tem a tarefa de codificar somente a camada imediatamente anterior. Esta rede treina de forma “gulosa” (greedy), ou seja, ela encontra a melhor solução local, que é considerada suficiente para a aplicação em questão, mas que não necessariamente representa a melhor solução global. Como parte da estrutura envolve representações probabilísticas dos dados, a rede pode ser usadas para gerar novos dados de saída, ou seja, novos estados de equilíbrio de um sistema.
Convolutional neural network (CNN) ou Deep convolutional network (DCN)

A rede neural convolucional tem uma estrutura bem diferente daquelas apresentadas até aqui. Nas camadas de convolução, a informação passa por vários filtros (que na prática são matrizes numéricas) com a função de acentuar padrões regulares locais, ao mesmo tempo em que vão reduzindo a dimensão dos dados originais. Os resultados de vários filtros são sumarizados por operações de pooling. Na parte mais profunda das convoluções, espera-se que os dados num espaço dimensional reduzido contenham informação suficiente sobre esses padrões locais para atribuir um valor semântico ao dado original. Esses dados passam então por uma estrutura de FFN clássica para a tarefa de classificação.
Por essas características, a aplicação mais comum das CNNs é na classificação de imagens; os filtros acentuam atributos dos objetos necessários à sua correta classificação. Uma CNN especializada em classificar rostos, por exemplo, nas primeiras camadas reconhece contornos, curvas e bordas; mais adiante, usa essa informação para reconhecer boca, olhos, orelha e nariz; e no final, reconhece o rosto inteiro. Além de imagens, qualquer informação com regularidade local pode se beneficiar do uso de CNNs, como áudio por exemplo.
Deconvolutional networks (DN)

A rede deconvolucional é, como o nome sugere, uma rede convolucional invertida. A partir de dados em um espaço dimensional reduzido, elas são capazes de “inflar” a informação para o espaço dimensional original.
Uma aplicação possível de DNs é, por exemplo, a geração de novas imagens. Imagine alimentar a rede com dados convolucionados para que ela gere novos rostos.
Deep convolutional inverse graphics network (DCIGN)

A rede profunda de gráfico inverso convolucional nada mais é que uma VAE que possui uma CNN como encoder e uma DN como decoder. Como ela aprende a representar a informação no espaço dimensional reduzido como uma distribuição probabilística, ela é capaz de gerar um dado “misto”, formado por dois dados que ela recebeu separadamente.
Imagine, por exemplo, uma rede convolucional especializada em classificar rostos de duas etnias diferentes. A DCIGN poderia gerar um rosto de uma etnia mista. Em outras palavras, ela poderia responder à pergunta: como seria o filho de duas pessoas dessas etnias?
Generative adversarial network (GAN)

A rede adversarial generativa pode ser descrita como contendo internamente duas redes que funcionam em conjunto, de forma competitiva. A primeira rede – a parte generativa – é responsável por gerar conteúdo, sendo treinada na tarefa de recriar a informação original. A segunda rede – a parte adversarial – é responsável por julgar o conteúdo, comparando a criação da rede generativa com a informação original. Quando a rede adversarial julga que a informação gerada não pode se passar pela original, a rede generativa é forçada a melhorar seu desempenho, até conseguir enganar a outra.
Isso faz com que as GANs tenham a capacidade de criar conteúdo inédito, já que a saída da rede foi produzida pela parte generativa e julgada aceitável pela parte adversarial. Isso pode ser considerada uma forma primitiva de criatividade, e por isso as GANs costumam ser citadas como artistas da inteligência artificial.
Liquid state machine (LSM)

A máquina em estado líquido é um tipo de rede neural com disparo. As funções de ativação são substituídas por uma função de limite, e cada neurônio tem também a função de memória. Dessa forma, quando o valor que o neurônio processa é atualizado, ele soma os valores que recebe como entrada ao valor que já possuía do processamento anterior, e “dispara” (ou seja, passa informação adiante) quando o referido limite é alcançado. Além disso, as conexões entre os neurônios são aleatórias.
De certo modo, essa representação é mais parecida com o que acontece em alguns processos no cérebro do que a rede neural clássica. Por isso, as LSMs costumam ter aplicação nas áreas de reconhecimento de fala e visão computacional, por exemplo.
Extreme learning machine (ELM)

A máquina de aprendizagem extrema é nada mais que uma rede neural profunda com conexões aleatórias entre as camadas. Ela também pode ser pensada como uma LSM sem memória e sem ativação por disparo. A principal diferença, entretanto, é que essa rede não é treinada pelo mecanismo de backpropagation, mas sim em uma etapa única, usando o ajuste do menor quadrado. Isso faz com que ela seja menos expressiva, mas seu treinamento é muito mais rápido.
ELMs podem ser aplicadas nos mesmos casos que as FFNs.
Echo state network (ESN)

A rede de estado de eco é uma rede neural recorrente com conexões aleatórias entre as camadas. A principal diferença, entretanto, também é relacionada ao método de treinamento, que não depende do mecanismo de backpropagation. Isso acabou, no momento de seu advento, aumentando a aplicabilidade da estrutura recorrente, já que, antes, as RNNs dificilmente eram usadas na prática, pois o treinamento costumava ser lento e nem sempre a convergência era garantida.
Atualmente, os problemas práticos das RNNs são considerados resolvidos, mas as ESNs ainda encontram aplicação nas áreas que dependem de dados computacionais não-digitais, como microchips óticos, nano-osciladores mecânicos ou próteses maleáveis, os quais não têm a mesma precisão numérica que dados digitais.
Deep residual network (DRN)

A rede residual profunda é uma FFN com muitas camadas, e que possui conexões extras ligando camadas não subsequentes. Dessa forma, as camadas mais profundas não recebem somente a informação da camada imediatamente anterior, mas também de outras camadas anteriores. Por causa dessa estrutura, as DRNs podem aprender padrões tendo até 150 camadas de profundidade – FFNs costumam ser limitadas a 5. Mas alguns trabalhos comparam o desempenho dessa estrutura com aquele de RNNs, sendo portanto as DRNs chamadas de RNNs sem a construção explícita de tempo, ou ainda LSTMs sem portão.
A aplicação é derivada das estruturas recorrentes que a DRN acaba emulando.
Neural Turing machine (NTM)

A máquina neural de Turing é uma abstração da LSTM, que tenta explicar o que a LSTM faz separando o neurônio que atualiza os dados que passam pela rede de seu componente de memória. As células de memória agem como um banco de memória que a rede neural consegue ler e sobrescrever, característica responsável pelo nome dessa arquitetura: ela pode representar qualquer coisa que uma Máquina de Turing Universal pode representar.
Em termos práticos, a NTM também pode ser pensada como uma LSTM, com a vantagem de que seu funcionamento é mais transparente.
Differentiable neural computers (DNC)

O computador neural diferenciável é uma NTM melhorada, com memória escalonável, inspirada pela forma com que o hipocampo armazena memória em humanos. Fazendo um paralelo com computadores, essa rede age como se a CPU fosse substituída por uma RNN, que aprende o que e quando ler da memória RAM. A memória pode ser redimensionada sem que a parte recorrente precise ser retreinada. A RNN pode determinar a similaridade dos dados de entrada aos valores contidos na memória, a relação temporal entre dois dados na memória, e se uma informação na memória foi atualizada recentemente.
Os autores do trabalho que introduziu essa arquitetura demonstraram seu potencial em responder perguntas sobre dados estruturados complexos, como histórias geradas artificialmente, árvores familiares, e até um mapa de metrô.
Capsule network (CapsNet)

A rede cápsula contém conexões entre os neurônios que são representadas por pesos múltiplos. Assim, cada neurônio consegue passar mais informação adiante, como, por exemplo, não somente a informação relacionada a um feature, mas também a posição, cor ou orientação do feature. Essa característica multi-informacional faz com que a rede cápsula tenha comportamento similar às camadas de pooling geralmente usadas para resumir as informações geradas nas camadas de convolução.
Essa arquitetura foi desenvolvida recentemente, buscando resolver algumas das deficiências das CNNs tradicionais, o que devem aumentar seu desempenho ou campo de aplicação original.
Kohonen network (KN)

A rede Kohonen também é chamada de mapa auto-organizável (self organizing map, SOM). Ela usa aprendizado competitivo para classificar os dados sem supervisão. Os dados de entrada são comparados com os valores dos neurônios (inicializados aleatoriamente) através de uma métrica de similaridade, e as conexões que representam maior similaridade são fortalecidas. Os neurônios então se ajustam para representar os dados originais de forma ainda mais similar, “arrastando” junto os neurônios em sua proximidade. Assim, ao final do treinamento, os dados originais podem ser classificados em clusters de similaridade na forma de um mapa definido pelos neurônios da rede.
Os SOMs são capazes de organizar dados para que os clusters formados possam ser explorados posteriormente. Por exemplo, eles podem indicar se um equipamento complexo está funcionando corretamente a partir das medições de sensores embutidos.
Attention networks (AN)

A rede de atenção é uma rede que usa a arquitetura chamada de transformer. A estrutura é bastante complexa, mas basicamente, o que essa rede faz é manter uma memória, cujo acesso é mediado pelo mecanismo de atenção, que define o grau de importância que cada informação da memória vai receber a cada passo. As ANs podem ser usadas em substituição às RNNs e redes derivadas, com a principal vantagem de que elas conseguem eliminar o componente temporal do processamento, o que permite paralelização e assim, treinamento mais rápido.
As ANs têm encontrado ampla aplicação na área de processamento de linguagem natural. Um dos modelos recentes mais bem-sucedidos, o BERT, faz uso dessa estrutura para produzir codificações dos dados com valor semântico suficiente para realizar tarefas complexas como classificar documentos, responder perguntas, identificar parafraseamento e até sarcasmo.
Excelente, informações muito valiosas, Sou professor pesquisador e estou iniciando o uso das redes neurais em minhas pesquisas, tenho aprendido bastante com vocês. Obrigado!
Que bom que gostou William 🙂
Top demais isso. Onde conseguimos ou tem cursos que exploram cada rede dessas?
Que bom que gostou Anderson! 🙂
Veja estes cursos
https://iaexpert.academy/courses/deep-learning-pytorch-python-az/
https://iaexpert.academy/courses/deep-learning-python-az-curso-completo/
Muito boa a explicação, bem objetiva e prática. Gostaria de saber se voces tem algum curso que explica sobre redes de estados de eco? Vi os cursos e sugeriu aqui nos comentários e não tinha nenhum que fala.
Que bom que gostou Aline! 🙂
Sobre esse assunto não temos
Olá, parabéns pelas explicações.
Sou concurseiro TCU-2021 e preciso urgentemente sobre linguagem Python e R, num nível básico-intermediário para fazer provas. Sou contador de origem, e apesar de alguns conhecimentos, a área de TI não é minha “praia”.
Agradeço toda ajuda possível. Abs e obrigado.
Olá Almir,
Nós não temos nenhum curso específico sobre essas linguagens, apenas aplicações delas nas áreas de machine learning. Te sugerimos procurar cursos na Udemy, a avaliação dos alunos ajuda a escolher cursos bons que vão atender sua necessidade.
Olá! Eu tenho interesse em fazer uma graduação em ciências de dados, porém, ao comparar as grades curriculares das instituições, não encontro disciplinas direcionadas ao estudo de Redes Neurais. Portanto, gostaria de saber se você pode me auxiliar nesse assunto, por favor.
Desde já, muito obrigada!
Olá, Kim! Temos vários cursos sobre esse assunto. Veja aqui a ordem: https://iaexpert.academy/trilhas/trilha-redes-neurais-e-deep-learning/
Dr Jones saudacoes, gostaria de saber se tem promocoes nos seus cursos da Udemy, gostaria de comprar um curso e receber mais 2.
Olá! Teve essa promoção no início do mês. A próxima será em novembro na Black Friday