
Uma das ferramentas de Visão Computacional que tem ganhado muita atenção nos últimos anos é o YOLO: You Only Look Once.
Após o seu lançamento em 2015, o YOLO foi logo reconhecido como uma técnica inovadora pois através de uma abordagem totalmente nova foi capaz de obter uma precisão igual ou superior ao dos outros métodos de detecção de objetos da época, porém com uma velocidade de detecção muito superior.

Enquanto as técnicas mais precisas levavam aproximadamente 0.5 segundos (ou mais) para processar uma imagem, o YOLO conseguia detectar com o mesmo nível de precisão em menos de 0.05 segundos, o que permitiu ser utilizado em aplicações de tempo real, sendo capaz de rodar até em uma taxa de 30 frames por segundo.
Outro motivo do sucesso do YOLO é o fato de ser totalmente código aberto e livre de licenças de uso. Ou seja, desde o código fonte, até a arquitetura da rede neural e os pesos pré-treinados, tudo isso pode ser usado por qualquer um e de qualquer forma.
Atualmente, essa técnica é considerada o estado da arte em detecção de objetos em tempo real. Em abril de 2020, quase 5 anos após o lançamento de sua primeira versão, o YOLO tem a sua quarta versão oficialmente publicada. Até o momento da data de sua publicação, o YOLOv4 é o detector de objetos com maior acurácia que permite ser executado em tempo real de acordo com os testes realizados utilizando o dataset MS COCO.
Confira abaixo uma demonstração do que o YOLOv4 é capaz de fazer:
O início do YOLO
O YOLO foi desenvolvido por Joseph Redmon e Ali Farhadi em 2015 durante o seu doutorado.
Em sua palestra na TED Talks, Redmon faz uma demonstração em tempo real da primeira versão do YOLO, quando sua arquitetura era um pouco diferente comparado à da versão atual, porém os conceitos principais continuam os mesmos.
Durante a apresentação, ele faz uma demonstração ao vivo provando que o detector é capaz de executar em sua GPU a detecção de até 80 categorias de objetos simultaneamente a uma taxa de mais ou menos 30 FPS, e mantendo uma ótima precisão, o que foi revolucionário para a época.
Assista abaixo Joseph Redmon apresentando o YOLO em sua palestra “How computers learn to recognize objects instantly”
Classificação de Imagens e Detecção de Objetos
Antes de compreender a importância do YOLO, vamos apenas revisar rapidamente o que é a detecção de objetos.
Diferente da classificação, que busca apenas prever a classe presente na imagem, a detecção de objetos além de prever qual é a classe precisa identificar também a localização do objeto nessa imagem.
Por exemplo, quando construímos um classificador de cachorro e gatos, o nosso classificador vai retornar como resultado da predição a classe (cachorro ou gato) e a confiança (grau de certeza sobre aquela predição).

Mas e se a imagem tiver tanto o gato quanto o cachorro? Poderíamos talvez treinar classificadores multi-classe que vão ser capazes de identificar as duas classes (tanto cachorro como gato).

No entanto, nós ainda não temos como saber a localização do cachorro ou gato na imagem. Esse problema de identificar a localização de um objeto (dada a classe) em uma imagem é chamado de localization (localização).
Ser capaz de predizer a localização do objeto na imagem junto com a classe do objeto (para múltiplas classes) é o que chamamos de Detecção de Objetos.
Mas afinal, o que é exatamente o YOLO? Qual sua vantagem para a detecção de objetos?
YOLO é um método de detecção de objetos de passada única (single pass) que utiliza uma rede neural convolucional como extrator de características (features).
Diferente de algoritmos anteriores de detecção de objetos, como R-CNN ou Faster R-CNN, ele apenas precisa olhar pela imagem uma única vez para enviar para a rede neural.
Por isso ele recebe esse nome (You Only Look Once – “Você só olha uma vez”).
E devido a essa característica, o YOLO foi capaz de conseguir uma velocidade na detecção muito maior do que as técnicas concorrentes, sem perder em acurácia.
Funcionamento
O YOLO trata a detecção de objetos como um simples problema de regressão.

1. Primeiro, o algoritmo divide a imagem em um grid de S x S células. Como exemplo usaremos 13×13, porém esse tamanho pode mudar. Para as versões mais recentes por exemplo tem-se preferido utilizar um grid de 19×19.
2. Cada uma dessa células é responsável por fazer a predição de 5 caixas delimitadoras (B), para caso haja mais de um objeto naquela célula. Também é retornado a pontuação de confiança que nos diz o quanto de certeza ele tem que aquela caixa delimitadora contenha um objeto.
3. Para cada caixa, a célula também faz a previsão de uma classe. Isso funciona como se fosse um classificador: é fornecido um valor de probabilidade para cada uma das classes possíveis. O valor de confiança para a caixa delimitadora e a predição da classe são combinados em uma pontuação final, que vai nos dizer a probabilidade dessa caixa conter um objeto específico.
Nesse caso o grid é 13×13, o que no final resulta em 169 células. Para cada uma dessas células são detectados 5 caixas delimitadoras, o que resulta em 845 no total.
4. Acontece que a maioria dessas caixas terá um valor de confiança extremamente baixo, então por isso geralmente se considera apenas as caixas cuja pontuação final seja 30% ou mais. Esse valor de 30% é o limiar, chamado de threshold, e ele pode ser alterado dependendo do quão preciso você quer que o detector seja.
Obs: Esse valor B (para as caixas delimitadoras) nesse exemplo é 5 porém pode mudar conforme a versão do YOLO. No YOLOv2 por padrão é = 5. Já no YOLOv3 o B = 3, porém é importante comentar que a partir dessa versão é feito a predição em 3 diferentes escalas, portanto vai ser mais de um feature map de saída com diferentes tamanhos (divide-se por 32, 16 e 8). Ou seja, para uma resolução de 416×416 serão 10647 boxes no total por imagem (416/32 = 13, 416/16 = 26, 416/8 = 52)
((52 x 52) + (26 x 26) + (13 x 13)) x 3 = 10647
Caso deseje saber mais sobre o funcionamento dessa etapa veja esse artigo aqui.
Darknet
Para o seu funcionamento o YOLO utiliza uma rede neural profunda, cuja arquitetura é chamada de Darknet, que é o mesmo nome do framework utilizado para implementar o detector.
Esse framework foi desenvolvido pelo próprio criador do YOLO, Joseph Redmon.
Ele é open source e escrito na linguagem C, também possui suporte para GPU.
O YOLO comparado a outras técnicas de detecção de objetos

Ao longo dos anos foram desenvolvidas diversas abordagens e metodologias para resolver esse mesmo problema da detecção de objetos. A técnica Haar Cascades (Viola e Jones, 2001) foi considerada a primeira abordagem a conseguir resultados realmente satisfatórios e que pudessem ser implementados em aplicações reais, sendo até hoje ainda bastante utilizada.
Poucos anos depois, em 2005, é apresentado o HOG – Histogram of Oriented Gradients (Navneet Dalal e Bill Triggs), o que também foi considerado um marco importante para essa área.
Mais tarde, com a ascensão do Deep Learning, foram desenvolvidos métodos baseados em Redes Neurais Convolucionais (CNN). Dentre os principais, podemos citar:
- R-CNN – Region-based Convolutional Neural Networks
- SPP-net – Spatial Pyramid Pooling
- Fast R-CNN
- Faster R-CNN
Com o tempo, esses algoritmos baseados em Deep Learning começaram a se tornar mais viáveis, pois no início era extremamente demorado para executar. Para se ter uma ideia, o R-CNN por exemplo levava 50 segundos aproximadamente para processar uma imagem, enquanto que o Faster R-CNN conseguiu anos mais tarde reduzir para 0.2 segundos.
E onde o YOLO se encaixa?
O YOLO veio logo depois, junto com o Faster R-CNN.
A vantagem do YOLO frente aos outros métodos é que esse faz as predições da classe com uma única passada na rede. Antes dele, esses outros principais sistemas de detecção de objetos faziam a detecção através da divisão da imagem em várias partes e depois em cada pedaço da imagem se executava um classificador, em cada uma dessas regiões (como é o caso do Haar Cascade por exemplo).
As pontuações altas retornadas por esse classificador eram consideradas detecções na imagem (ou seja, os próprios objetos).
Podemos usar um classificador como VGGNet ou Inception e transformá-lo em um detector de objetos se usarmos uma janela que se desloca pela imagem (sliding window). Em cada etapa é rodado um classificador para obter uma predição a respeito de que tipo de objeto é dentro da janela. Usando a janela deslizante pode-se retornar centenas ou milhares de predições para aquela imagem, mas mantemos apenas aquelas que o classificador possui uma certeza maior.
Isso significa que é necessário rodar o mesmo classificador dezenas ou milhares de vezes sobre a mesma imagem. Mas diferente de quando estamos usando uma abordagem clássica como o Haar Cascade, ao lidarmos com uma técnica que utiliza redes neurais artificiais (ou seja, baseada em Deep Learning) é muito demorado e pesado executar a mesma operação sobre a imagem milhares de vezes, ainda mais se for rodar isso em condições normais usando um computador convencional.
Comparando com esses outros métodos, o YOLO possui uma abordagem completamente diferente. Ele não é um classificador tradicional que foi reajustado para ser um detector de objetos, mas sim foi feito para ser capaz de rodar por toda a imagem apenas de uma vez, fazendo isso de uma forma inteligente.
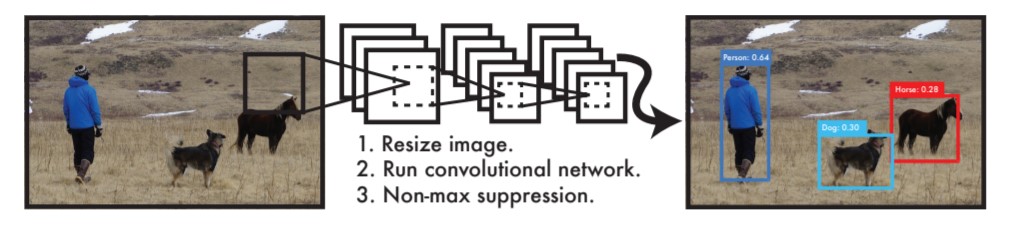
Desse modo, com o método YOLO é possível realizar a detecção em tempo real, ou quase real dependendo das configurações de hardware da máquina onde está sendo rodado.
A evolução do YOLO
Joseph Redmon introduziu a primeira versão em seu paper publicado em junho de 2015: You Only Look Once: Unified, Real-Time ObjectDetection.
Em dezembro de 2016, Redmon e Ali Farhadi introduziram o YOLOv2 com o paper: “YOLO9000: Better, Faster, Stronger. Mais preciso e mais rápido que a versão anterior.
Em abril de 2018, o YOLOv3 (“YOLOv3: An Incremental Improvement“) demonstrou uma grande melhora na eficiência da predição. No entanto, no geral ele não é mais rápido que a versão anterior. A principal novidade é a predição da imagem em 3 diferentes escalas, o que resolveu o principal problema da versão anterior que era a dificuldade para reconhecer objetos muito pequenos na imagem. Essa novidade também é o principal motivo de não ser mais rápido que o seu antecessor, já que tal função exigiu mudanças na arquitetura e funcionamento, que tornaram o processo mais pesado.
YOLOv4 – Mais rápido e mais preciso
A quarta versão do YOLO foi lançada em abril de 2020, sendo oficializada após a publicação do paper “YOLOv4: Optimal Speed and Accuracy of Object Detection” por Alexey Bochkovskiy, Chien-Yao Wang e Hong-Yuan Mark Liao.
As principais características que podem ser destacadas nessa versão são a melhoria na velocidade de inferência e acurácia. Outra característica importante é o fato de ser mais eficiente para rodar em GPUs, pois foi otimizada para utilizar menos memória.
Mas o quão bom essa nova versão realmente é?
O YOLOv4 demonstrou ser o melhor detector de objetos para testes em tempo real de acordo com as métricas do MS COCO, um famoso dataset utilizado para avaliar os sistemas de detecção de objetos.
Além de ser mais rápido e mais preciso que o EfficientDet, o YOLOv4 também supera o RetinaNet/MaskRCNN (Facebook Pytorch/Detectron) no dataset COCO.
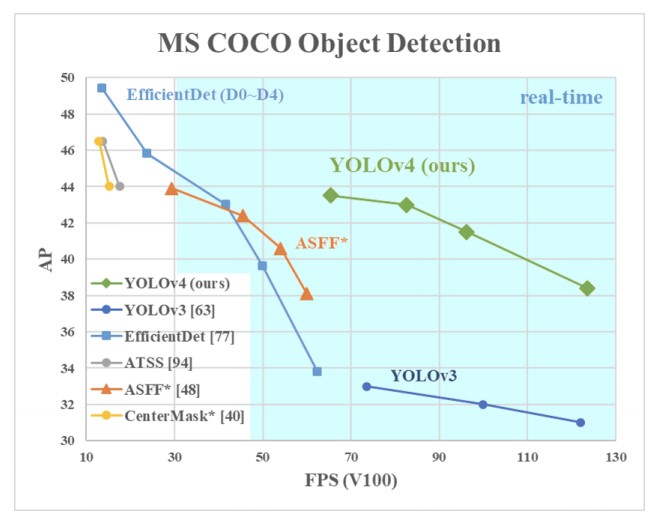
O que os autores do YOLOv4 fizeram foi melhorar essa arquitetura através de inúmeras otimizações realizadas.
A sua arquitetura final consiste em:
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
Além disso, foram implementadas várias técnicas modernas. Umas das novidades mais importantes foi a introdução de um novo método de data augmentation chamado de Mosaic e Self-Adversarial Training (SAT).
Implementando o YOLO para detecção de imagens
Primeiramente vamos clonar o repositório do darknet (por AlexeyAB, o mais atualizado atualmente), que contém todos os arquivos e ferramentas necessárias para fazer a implementação do YOLO.
!git clone https://github.com/AlexeyAB/darknet
Em seguida vamos acessar o diretório
%cd darknet
Agora vamos compilar o Darknet usando o comando “make”
!make
O YOLO por padrão já foi treinado com o conjunto de dados do MS COCO, que possui 80 classes diferentes. Vamos pegar esses pesos pré-treinados para que possamos executar o YOLO v4 nessas classes pré-treinadas. Precisamos baixar separado pois esses pesos possuem mais de 200mb.
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
Agora estamos com tudo pronto para realizar os testes. Para rodar a detecção utilizaremos o seguinte comando
!./darknet detect <arquivo config> <arquivo dos pesos> <imagem>
Veja um exemplo abaixo:
./darknet detect cfg/yolov4.cfg yolov4.weights data/person.jpg

O teste acima foi executado no Google Colab utilizando a GPU Tesla T4. O tempo total de processamento foi de aproximadamente 0.07 segundos.
Portanto, com esse teste podemos comprovar como o YOLO consegue processar a imagem com uma impressionante velocidade nas GPUs, enquanto mantém uma ótima precisão em sua detecção.
Assim como vários outros sistema de detecção de objetos, o YOLO é de uso geral, o que significa que ele pode ser usado para muitos propósitos diferentes, basta treinar para qualquer categoria de imagem que você deseja detectar.
O mesmo código usado para encontrar pessoas ou animais pode ser usado para encontrar células cancerígenas em uma biópsia de tecido, por exemplo.
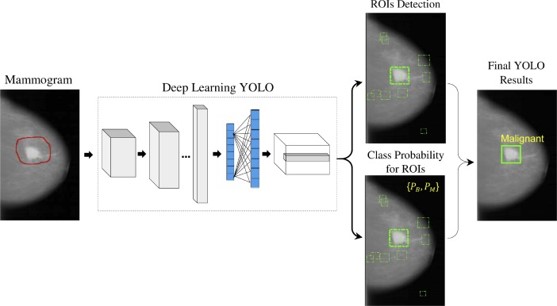
Há pesquisadores no mundo todo que já utilizam essa tecnologia, o que permitiu o avanço em várias áreas como medicina e robótica.
Além disso, podemos ver a detecção de objetos sendo utilizada em várias outras aplicações modernas, desde em rastreamento de objetos e nos aplicativos do seu celular, até em veículos autônomos, que já são uma realidade nos dias de hoje em muitos locais do mundo e aos poucos vão ganhando cada vez mais espaço.
Referências
- YOLOv4 Paper – https://arxiv.org/abs/2004.10934
- YOLO: Real-Time Object Detection – https://pjreddie.com/darknet/yolo/
- Convolutional Neural Networks – Andrew Ng – https://www.coursera.org/learn/convolutional-neural-networks/lecture/yNwO0/anchor-boxes
Muito bom, apenas uma correção o Yolo gera 3 Bounding Boxes… Se a fonte utilizada foi esta: (https://dzone.com/articles/understanding-object-detection-using-yolo), ela está mal interpretada pois na própria referência usada(https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b) diz de forma correta B = 3.
Olá Diogo, muito obrigado pelo comentário!
Sim, pelo que observei há uma confusão quanto a isso.
A fonte que você citou não foi a que nos baseamos, porém ambas comentam a mesma informação. Na realidade elas não se contradizem, o único detalhe que faltam mencionar é que na prática o B padrão pode mudar dependendo de cada versão. No YOLOv2 vemos que o B por padrão é = 5 (por isso a formula resulta em 845 com um grid de 13×13). Inclusive na outra fonte que você citou é comentado isso, já que são 5 caixas para cada célula, que é o número de anchor boxes.
Se você procurar exemplos na internet esse vai ser o mais comum que vai achar, até porque nessa versão foram introduzidos os anchor boxes e com isso teve uma grande mudança em relação à versão anterior referente a essa etapa, portanto a escolha da v2 como base para explicação desse conceito do YOLO é comum, mas por isso logo abaixo também achei melhor comentar sobre mudança na arquitetura do YOLOv3 referente às escalas.
Já na v3 o B = 3 conforme você disse, mas note que na v3 é feito a predição em 3 diferentes escalas portanto vai ser mais de um feature map de saída com diferentes tamanhos (divide-se o feature map por 32, 16 e 8).
Para uma resolução de 416×416 serão 10647 boxes no total por imagem (416/32 = 13, 416/16 = 26, 416/8 = 52)
((52 x 52) + (26 x 26) + (13 x 13)) x 3 = 10647
E como são 3 escalas na verdade o número de âncoras será 9 e não 3.
Essa fonte que você passou já explica bem essa parte.
Nesse post não mencionamos tudo pois haveria a necessidade de introduzir vários outros conceitos e a ideia era resumir ao máximo a parte teórica, no entanto, devido ao seu comentário vou deixar uma observação ali logo abaixo na parte do Funcionamento a respeito desses detalhes que comentamos
obrigado =)
Excelente matéria. Muito obrigado!
Que bom que gostou Evandro 🙂
Está de parabéns, amigo. Foi a explicação mais didática e completa que achei em português até agora.
Que bom que gostou, Helton! Veja também o curso que temos aqui na plataforma 🙂
https://iaexpert.academy/courses/deteccao-de-objetos-com-yolo-darknet-opencv-e-python/
Perfeito! Sou iniciante em Python e recentemente apareceu uma necessidade que se encaixa examente com essa abordagem.
Acabei de me tornar assintante motivado por essa abordagem moderna.
Obrigado.
Legal, Leornardo! Esperamos que aproveite os cursos 🙂
Professor estou tendo problema com código fonte da yolov8, pode me auxiliar para resolver este problema?
Olá! Poste a dúvida no fórum do curso, que a equipe de suporte responde por lá (link no canto superior esquerdo da aula)
Existe uma possiblidade de aumentar a eficiência dos modelos de reconhecimento de objectos? Relativamente a ao artigo gostei bastante! Muita informação boa.
Olá Marques!
Sim, existem várias opções. Por “eficiência” acredito que você se refira à aumentar a performance do tempo de detecção, isso?
A primeira medida para otimizar seria fazer o upgrade do hardware da máquina onde está sendo executado, usando uma boa GPU é possível rodar dezenas de detecções por segundo e assim pode deixar tranquilamente sua aplicação em tempo real por exemplo. Mas caso não tenha uma GPU, saiba que hoje é possível ter uma boa velocidade com uma CPU mediana/boa (mas claro, quanto melhor mais velocidade você observa).
Porém é compreensível que o upgrade do hardware não seja uma opção em boa parte dos casos. Como alternativa para melhorar a performance, é possível usar versões mais leves do modelo.
Por exemplo, o YOLOv4 possui a chamada versão “tiny” que é mais leve. E nas versões mais recentes (YOLOv8) tem sido disponibilizado variações para carregar os modelos menores também (versão nano e small), podendo ou não comprometer levemente a acurácia em troca por um ganho considerável na velocidade de detecção. Com isso é possível fazer detecções extremamente rápidas até mesmo com CPUs.
Para otimizar mais ainda na CPU você pode converter para o formato ONNX ou OpenVINO.
E para acelerar executando na GPU recomenda-se exportar para o TensorRT.
Para detalhes de como fazer pode consultar a documentação oficial -> https://docs.ultralytics.com/modes/export/#arguments.
Outra maneira seria reduzir o tamanho da imagem de entrada, porém isso é algo que pode prejudicar um pouco na precisão também caso os objetos na sua imagem ou vídeo apareçam muito pequenos.
Já se você se por “eficiência” você quis se referir à precisão da detecção, saiba que também é possível. Não só o YOLO mas outras abordagens modernas para detecção de objetos permitem melhorar bastante a acurácia. Isso é discutido no curso sobre YOLO aqui na plataforma, mas existem inúmeras maneiras, o que geralmente se baseia num processo de bastante experimentação e testes.
Fala gabriel, eu utilizei o Yolo em um trabalhho e a versão 4 demostrou resultados melhores que a versão 8. Sabe porque se deve essa diferença? usei o mesmo data set e treinei bastante e, em alguns casos, o Yolo v8 não detectou nem o objeto na imagem, já a v4 sim.
Olá Juan!
Embora difícil pode ocorrer, geralmente é complicado comparar modelos de forma tão direta, pois há muitas coisas que são levadas em consideração ao compará-los. É totalmente possível que um modelo v4 forneça melhores resultados do que um modelo v8 se o conjunto de dados for mais adequado à estrutura do modelo, ou se os hiperparâmetros padrões forem mais ajustados em favor de um. Outra possibilidade (que imagino que possa ter sido o caso, se você treinou por muito tempo) é ter ocorrido o overfitting. Por isso, observe os gráficos gerados pelo v8 após o treinamento, lá você consegue observar as métricas e assim concluir se ocorreu o overfitting ou não.
A qualidade do resultado vai depender muito do dataset também. Verifique se ele possui uma quantidade satisfatória de amostras para cada objeto a ser detectado (e se possui um conjunto de validação adequado também), caso não então recomendo usar data augmentation, assim vai ajudar o modelo a generalizar melhor. Mais importante ainda é garantir que dataset possua uma boa qualidade de imagens e que está bem rotulado, com as bounding boxes marcadas certas.
E qual tamanho de modelo você usou para o treinamento? (ex: small, large, extra large). Como depende totalmente do dataset que você está trabalhando, pode ser que seja o caso de um objeto que exija uma arquitetura mais pesada, como objetos que possuem detalhes muito finos, então você pode tentar treinar a partir do yolov8l ou yolov8x. Além de ser mais pesado para treinar vai ser mais demorado para executar, então se sua aplicação exigir detecção em tempo-real essa ideia não é tão interessante.
Mas mesmo que seja o tamanho normal (YOLOv8m) creio que deveria conseguir resultados minimamente bons se treinar usando os parâmetros certos e por tempo o suficiente.
Por isso, é bom antes só rever aquelas outras questões e então aí sim treinar com modelos maiores.
E para otimizar o treinamento também faça o fine-tuning dos hiperparâmetros (learning rate, weight decay, momentum).
Você pode conferir detalhes sobre os parâmetros aqui
https://docs.ultralytics.com/usage/cfg/#train
GABRIEL ALVES, Muito obrigado! Como faço para entrar em contacto com você ou com professor do curso? ( Por favor ).
É possível utilizar o Yolo para detectar um passe ou um gol em uma partida de futebol? Sei que é possível rastrear jogadores e a bola.
Olá Renato! Sim é possível. Para detectar eventos mais complexos ou específicos pode ser necessário combinar com algoritmos de rastreamento de imagem.
Para isso que comentou, primeiro precisaria ter o modelo de detecção de objetos treinado para identificar pelo menos a bola e a trave (caso não consiga achar um modelo treinado para isso, terá que treinar o seu, usando um dataset apropriado para os vídeos onde você rodará o programa). Tendo esse modelo treinado você consegue em seguida implementar a lógica para identificar também mais eventos importantes já que terá o modelo capaz de detectar os “objetos” que estão envolvidos nesses momentos.
Para o gol, uma ideia talvez seria treinar um modelo para detectar exatamente a presença da bola dentro do gol, assim quando ocorrer isso você consegue determinar facilmente no programa quando ocorreu, basta verificar se no frame há a presença desse “objeto”. Ou, o que provavelmente seria mais preciso, é detectar antes a trave e então rodar dentro da área de interesse dela (e apenas dentro dessa área) para verificar se foi ou não detectado o objeto da classe bola – se houver uma ocorrência dentro dessa área então indica que houve o gol.
Parabéns pelo conteúdo incrível da página! É fascinante explorar as inúmeras possibilidades que o YOLO oferece. No entanto, não podemos deixar de lado a preocupação com a capacidade de processamento necessária. É verdade que modelos menores podem não tema eficiência desejada, enquanto os maiores parecem exigir uma usina nuclear para serem processados — (uma ironia), mas que também levanta um ponto importante sobre a necessidade de otimização. Continuem com o excelente trabalho!
Obrigado pelo feedback 🙂
Ola, eu preciso separar individuos por foto, vi em um artigo que uns autores separaram leopardos usando o YOLO Algorithm, existe alguem tipo de apoio aqui que possa me ajudar nessa tarefa? é identificaçao de uma especie de ave, usando ciencia-cidada. Obrigada
Olá Adriani!
É possível sim usar o YOLO para identificar e separar indivíduos de uma espécie de ave em fotos, assim como foi feito no exemplo com leopardos. Essa abordagem é bastante eficiente para tarefas de detecção, podendo aprender a reconhecer praticamente qualquer tipo de objeto ou classe. No seu caso, bastaria coletar um conjunto de imagens de aves rotuladas corretamente e treinar o modelo para reconhecer essas variações.
Para esse tipo de projeto específico eu não vi uma solução pronta, mas parece que pode isso que você citou pode ser feito através do treinamento de um detector customizado, o que fará detectar apenas aquilo que você treinou. Se precisar de ajuda com a implementação, temos na plataforma um curso dedicado ao YOLO, onde é ensinado como configurar o modelo para detectar na imagem somente os objetos desejados.
Olá, estou fazendo meu TCC na área da construção civil com o objetivo de detectar o uso EPIs, é possível utilizar Yolo em qualquer programação, sou um pouco leiga no assunto e estou pesquisando mais sobre, mas achei muito interessante, poderia me ajudar a alinhar esse pensamento ?
Olá Amanda! Sim, é totalmente possível usar o YOLO para detectar o uso de EPIs na construção civil. O YOLO é um modelo eficiente de detecção de objetos que pode ser treinado para identificar diferentes tipos de EPIs como capacetes, luvas, óculos de proteção ou qualquer outro tipo de objeto. E sim ele pode ser implementado em várias linguagens de programação, a que mais recomendamos para isso é Python. Também pode ser integrado a frameworks populares de deep learning, como TensorFlow ou PyTorch. Mesmo que você seja iniciante, há muitos tutoriais e recursos disponíveis para te guiar no processo de treinamento e implementação, que nas versões mais recentes está mais prático de se realizar.
Mas caso esteja com dificuldade ou queira aprender mais, aqui na plataforma tem um curso focado somente no YOLO e detecção de objetos, onde é ensinado com detalhes todo o passo a passo desde a configuração do ambiente até o treinamento do modelo.
Gabriel, estou precisando de um dev que tenha expertise com Yolo, tu é?
Olá Filipe! Atualmente não estou trabalhando como dev com YOLO, mas dependendo da necessidade pode ser que eu consiga te auxiliar de algum modo. Se quiser pode enviar uma mensagem ali na página de contato (https://iaexpert.academy/contato/)