- This topic has 1 reply, 2 voices, and was last updated 2 years, 12 months ago by
 .
.
Viewing 2 posts - 1 through 2 (of 2 total)
Viewing 2 posts - 1 through 2 (of 2 total)
- You must be logged in to reply to this topic.
Home › Forums › Fórum Reconhecimento de Textos com OCR e Python › Código não identifica a palavra “begin”
Tagged: Detecção em cenários naturais
Segue em anexo as imagens. O algoritmo não conseguiu ler a palavra begin:
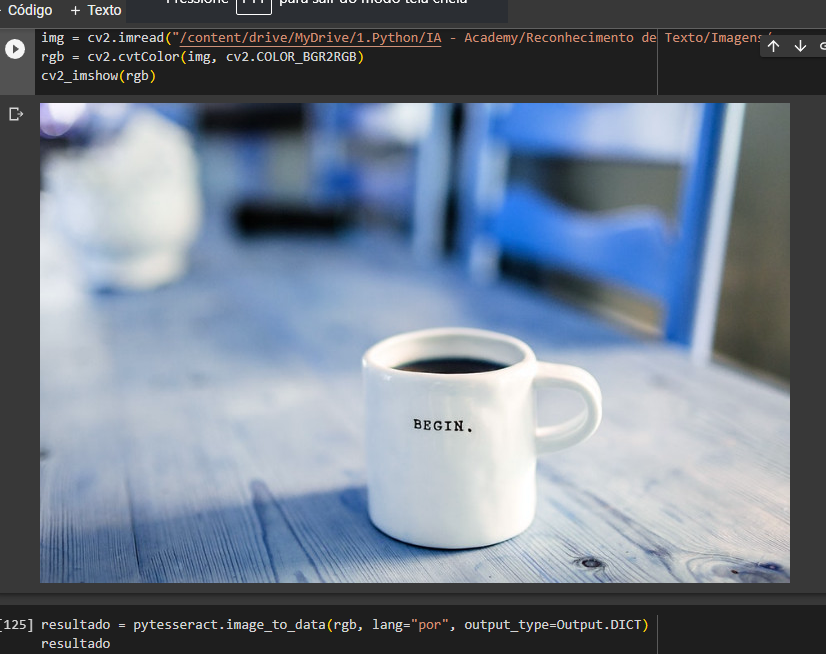
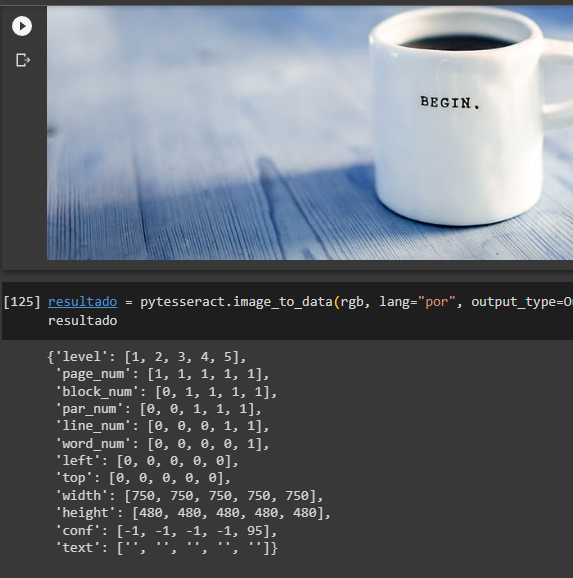
Olá Artur!
Isso ocorre porque provavelmente em uma versão recente da biblioteca houve uma alteração pequena no algoritmo mas que foi o suficiente para influenciar no reconhecimento de algumas imagens mais “desafiadoras” (como essa, de um cenário natural). Para identificar agora a palavra BEGIN com essa imagem precisa mudar o parâmetro, deixando “psm 11” por exemplo consegue fazer o OCR do texto na caneca dessa imagem. O código fica assim então:
config_tesseract = "--tessdata-dir tessdata --psm 11" resultado = pytesseract.image_to_data(rgb, config=config_tesseract, lang="por", output_type=Output.DICT)
Nas aulas das próximas sessões verá formas melhores de reconhecer textos em cenários naturais, então nem se preocupe muito agora em ficar escolhendo o melhor parâmetro para pegar o texto usando o Tesseract. Há métodos mais eficazes nessas situações (como por exemplo, fazer a detecção do texto antes do OCR, ou usar outro algoritmo como o EasyOCR que já oferece a localização de texto embutida no comando), e lá nessas aulas vai ser explicado o porquê são melhores nesses casos.