Home › Forums › Domine LLMs com LangChain › Projeto 3
- This topic has 6 replies, 3 voices, and was last updated 1 year, 5 months ago by
 Gabriel Alves.
Gabriel Alves.
-
AuthorPosts
-
31 de dezembro de 2024 at 16:24 #47146
Olá
Estou executando o projeto 3 Converse com Seus Documentos, localmente e tenho algumas dúvidas:
A IA não consegue responder algumas perguntas como mostrado na vídeo aula. Por exemplo: Ela responde que o Dr. Watson é um personagem ficticio da historia de Sherlock Holmes. Perguntei sobre os outros fundadores da BlueNexus e ela não soube responder.
Quando clico nas fontes da resposta, vejo que no conteúdo, as palavras estão todas juntas sem espaçamento. Isso pode estar prejudicando a IA quando procura as respostas?
Com relação ao longo tempo para responder a primeira pergunta, imagino que seja pelo processo de carregamento dos documentos e indexação do vectorstore. Esse processo não poderia ser feito em separado por outro aplicativo e ao iniciar o chat este já acessaria o vectorstore pronto? Isso tornaria o inicio mais rápido?
Haveria alguma limitação do tamanho do arquivo? Poderia colocar um livro em PDF por exemplo?
No mais, só tenho que agradecer. Excelente didática e conteúdo.
3 de janeiro de 2025 at 10:13 #47159Olá Fernando,
Primeiramente, agradeço o feedback positivo! Vamos às suas dúvidas:
Em relação às respostas incorretas da IA, pela sua descrição parece que o modelo está usando somente conhecimento prévio ou não está encontrando os dados no banco vetorial corretamente. Você comentou que o texto apareceu juntas sem espaçamento, isso mostrou quando clica em cima do botão (popover) para ver a fonte? Se puder mandar um print de onde aparece, pode até ser que seja um bug do streamlit e que nessa caixinha está exibindo o texto sem os espaços ao final de cada bloco. O problema de palavras sem espaçamento poderia estar prejudicando sim a indexação e a recuperação, mas se foi utilizado exatamente o código da aula então não deveria ocorrer pois a função exata já faz esse processamento correto do texto antes de enviar à rede neural (mas só para testar, poderia usar também outro método que faz o pré-processamento do texto). Recomendo fazer novamente o envio dos documentos e testar diferentes parâmetros para o ‘k’ e ‘fetch_k’, dentro de vectorstore.as_retriever().
Quanto a melhorar o tempo de resposta inicial, você está correto. O carregamento e a indexação podem ser feitos separadamente, em um aplicativo à parte. Isso permite iniciar o chat acessando diretamente o vectorstore já pronto, reduzindo significativamente o tempo de resposta inicial. E caso o arquivo seja enviado apenas uma vez e não mude então pode salvar em disco, assim não precisa executar a indexação toda vez que inicia o app. Para mais velocidade no tempo de indexação/recuperação, sugiro dar uma olhada no Pinecone, que pode ser facilmente integrado com o LangChain, basicamente precisa apenas mudar os métodos para integração e assim pode reaproveitar todo o restante do código (veja mais).
E em relação às limitações de tamanho do arquivo, é possível sim carregar arquivos grandes porém o processamento e a indexação podem levar mais tempo e consumir mais memória, portanto precisa verificar se o hardware é adequado ou se vale mais a pena usar soluções que rodam em cloud como o Pinecone. Para PDFs extensos, como livros, recomenda-se dividi-los em chunks menores para facilitar o processamento e melhorar a recuperação de informações durante as consultas. A abordagem correta é experimentar diferentes parâmetros para o método do retriever, o que tenderá a funcionar melhor para documentos bem maiores.
-
This reply was modified 1 year, 5 months ago by Gabriel Alves.
5 de janeiro de 2025 at 10:23 #47163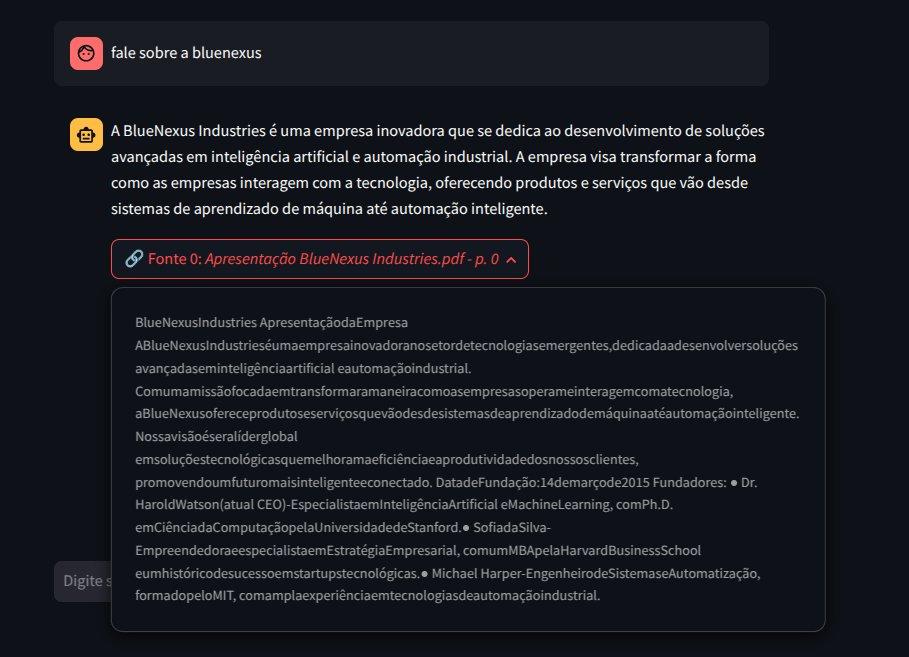
Olá Gabriel.
Segue o print do problema das palavras sem espaçamento.
8 de janeiro de 2025 at 08:54 #47178Opa, parece ser algo que afeta a pré-visualização somente, mas para garantir você consegue me passar a versão do LangChain e a versão do Streamlit que tem instalado em sua máquina local? Para eu tentar reproduzir o problema daqui, já que em meus ambientes está funcionando conforme esperado
8 de janeiro de 2025 at 11:10 #47182Aqui mesmo bug na fonte, tudo junto, segue as versões usadas aqui:
faiss_cpu==1.9.0.post1
langchain==0.3.14
langchain_community==0.3.14
langchain_core==0.3.29
langchain_huggingface==0.1.2
langchain_ollama==0.2.2
langchain_openai==0.2.14
langchain_text_splitters==0.3.5
python-dotenv==1.0.1
streamlit==1.41.1
torch==2.5.1+cu124rodando via GPU.
8 de janeiro de 2025 at 12:19 #47183Descobri o problema é o PDF enviado.
Testei com outros PDF e funcionou, ao abrir o pdf enviado com o word e salvo novamente, tudo funcionou.
tinha feito esse código para testar rapidamente os pdf
from langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader("teste3.pdf") pages = loader.load() for page in pages: print(page.page_content)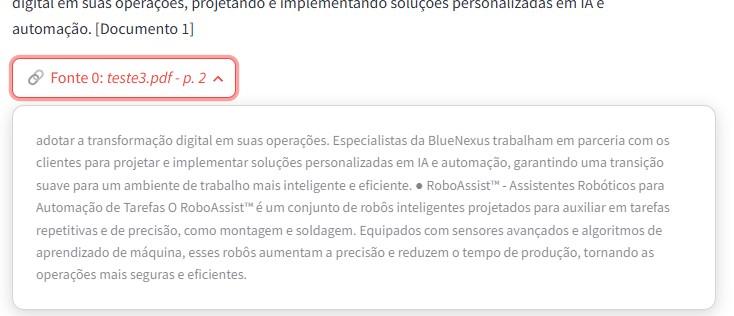
-
This reply was modified 1 year, 5 months ago by
Leonardo D.
-
This reply was modified 1 year, 5 months ago by
10 de janeiro de 2025 at 13:11 #47266Que ótimo que conseguiu descobrir
Esse problema deve ocorrer porque alguns PDFs possuem conteúdos mal formatados ou usam codificação que dificulta a extração adequada do texto, resultando em palavras juntas ou sem espaçamento. Talvez quando você abriu o PDF com o Word e salvou novamente, o Word automaticamente reformatou o texto e com isso corrigiu essas inconsistências.
Para evitar isso no futuro, você pode usar ferramentas como PyPDF2 ou pdfplumber para inspecionar e corrigir problemas nos arquivos antes de carregá-los com o PyPDFLoader. Ou ainda, converter em um arquivo de texto ou outro formato legível antes de enviar o conteúdo para o RAG.
Se quiser também pode testar outros loaders de PDF que o LangChain suporta, como PyMuPDFLoader ou PDFMinerLoader. Mais informações aqui: https://python.langchain.com/docs/integrations/document_loaders/
Para lidar com PDFs com formatos inconsistentes, o uso de serviços como o Unstructured (que o LangChain também suporta) pode ser uma ótima solução para extrair textos de maneira mais robusta. Para mais informações sobre ele veja https://python.langchain.com/docs/integrations/document_loaders/unstructured_file/ – aliás também deixamos comentários sobre no final do Colab do projeto 03 (aqui)
-
This reply was modified 1 year, 5 months ago by
-
AuthorPosts
- You must be logged in to reply to this topic.