Home › Forums › Fórum Reconhecimento de Textos com OCR e Python › TesseractError
- This topic has 4 replies, 2 voices, and was last updated 4 years, 10 months ago by
 Gabriel Alves.
Gabriel Alves.
-
AuthorPosts
-
13 de setembro de 2021 at 20:14 #30767
Olá, tudo bem?
Gostaria de retirar uma dúvida sobre um problema que estou tendo.
Estou fazendo o curso de “Reconhecimento de texto com OCR e Python”, pois bem, compilei o arquivo fonte do primeiro tópico, sem problemas, quando tentei os arquivos dos outros tópicos tive como retorno erro, tentei voltar então ao primeiro código que inicialmente funcionava, o mesmo também passou a apresentar erro, segue abaixo a mensagem para visualização:
TesseractError: (1, ‘Error opening data file tessdata/por.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your “tessdata” directory. Failed loading language ‘por’ Tesseract couldn’t load any languages! Could not initialize tesseract.’)
Estou tentando realizar a etapa “Processamento do vídeo e exibição do resultado” do conteúdo OCR em vídeos.
A execução dos códigos está sendo feita no Google Colab com a cópia do código fonte original.
Gostaria de uma orientação em como devo proceder neste caso.
Obrigado.
Atenciosamente.
Fernando Guizã
13 de setembro de 2021 at 20:53 #30768Este é o erro completo que está retornando:
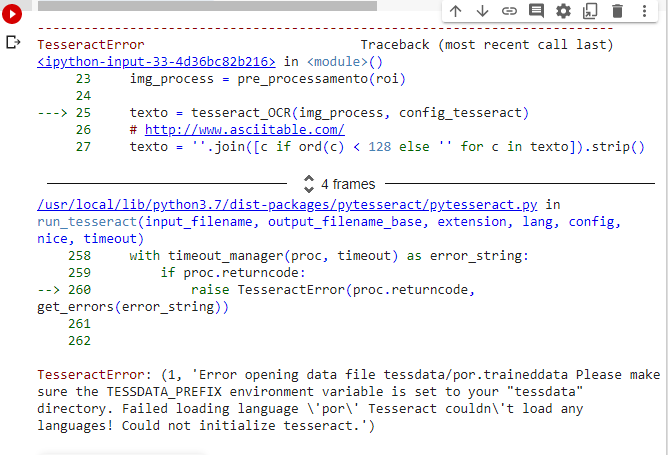
Não foram realizadas alterações do código original.
Obrigado.
Att.
15 de setembro de 2021 at 11:48 #30785Olá Fernando!
Acredito que tenha ocorrido algum problema para baixar o arquivo de tradução (por.traineddata), provavelmente foi feito o download mas não do arquivo bruto (pode acontecer as vezes)
veja quanto pesa o arquivo por.traineddata, ele tem que pesar aproximadamente 14mbSe ainda estiver com problemas para baixar então substitua em seu código (na linha do !wget) o link abaixo
de:
https://github.com/tesseract-ocr/tessdata/blob/master/por.traineddata?raw=truepara:
https://github.com/tesseract-ocr/tessdata/blob/main/por.traineddata?raw=trueOu seja, o comando ficará assim
!wget -O ./tessdata/por.traineddata https://github.com/tesseract-ocr/tessdata/blob/main/por.traineddata?raw=true
Após baixar esse arquivo e substituir o que baixou anteriormente faça os testes novamente.
15 de setembro de 2021 at 22:30 #30792Obrigado Gabriel,
Fiz o ajuste conforme orientado e consegui prosseguir, entretanto algumas etapas após (“Processamento do vídeo e exibição do resultado”), ocorreu um erro, ele aparentemente processou as imagens e exportou o arquivo de vídeo, entretanto o arquivo ficou com apenas 2 segundos ao invés de 4 segundos que deveria possuir.
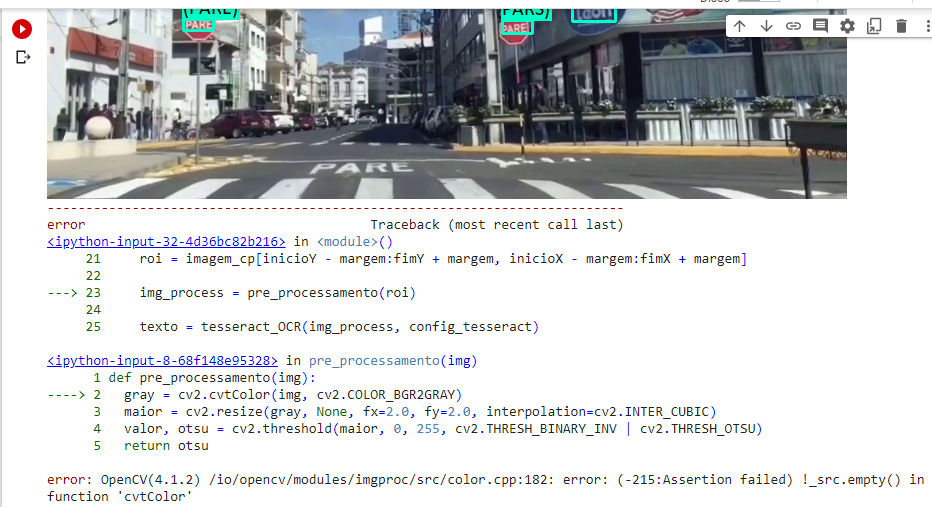

Rodei o tópico posterior (“OCR em vídeos com EasyOCR”) e ele não apresentou erros, retornando o vídeo com 4 segundos.
Solicito novamente auxilio para a resolução do problema.
Desde já agradeço a atenção.
Obrigado.
Atenciosamente.
18 de setembro de 2021 at 11:19 #30829Olá Fernando,
Verifique se o vídeo foi baixado corretamente, pois esse erro pode ocorrer quando há algum problema para ler algum frame do vídeo. Verifique também se todas as células do Colab foram executadas. Caso esteja tudo ok, faça o seguinte: “Runtime > Factory reset runtime” (se o seu estiver em português fica: “Ambiente de Execução > Redefinir o ambiente de execução para a configuração original”)
E execute seu código novamente.
Caso o erro permaneça, peço que compartilhe aqui seu Colab para poder auxiliar melhor.
Mas de preferência compare antes o seu código com esse aqui: https://colab.research.google.com/drive/1a8iChq_1_vgbokpk5VXPWzjTe2lhdqJj?usp=sharing
-
AuthorPosts
- You must be logged in to reply to this topic.