Forum Replies Created
-
AuthorPosts
-
Olá Anderson, fiz mais algumas verificações aqui e está funcionando ok a opção de marcar como concluído, talvez algo no seu computador ou navegador que esteja impactando e causando interferência a ponto de não marcar como concluído assim que você finaliza, ou pode ser também algum problema relacionado ao cache. Poderia tentar novamente acessando através de outro navegador? ou acessando do celular caso tenha tentado antes pelo computador (ou vice-versa).
Se o problema persistir, peço que me descreva o que aparece na sua tela assim que concluiu a aula (ou envie um print se puder). me confirme se ao terminar a aula:
- a página é recarregada;
- o botão muda de cor.
Em último caso, enquanto não funciona ok essa função pra você eu posso marcar como concluído por você as aulas que já viu, se preferir basta me passar aqui até qual aula viu
Olá Anderson!
Verificamos aqui no sistema e a princípio deveria estar marcando ok, talvez seja algum problema temporário ou relacionado ao cache de seu navegador (ou algum plugin que poderia causar interferência).
Assim que chega ao final da aula (ou quando clica no botão abaixo do vídeo) é marcado como concluído, se não atualizou experimente recarregar a página e verificar novamente no painel lateral.
Como deveria ser: https://drive.google.com/file/d/1u30ZPMjGrBnx5KFxHiFGcWRv83vZ5Iam/view?usp=sharing
Se ainda continuar esse problema para você, basta enviar mensagem para nós aqui com um print do que aparece na sua tela assim que conclui a aula
-
This reply was modified 1 week, 6 days ago by
 Gabriel Alves.
Gabriel Alves.
8 de junho de 2026 at 22:41 in reply to: Erro de compatibilidade de versão ao carregar os pesos da R-CNN #54975Olá Leonardo!
Para evitar esse problema, use a versão 2.17 do tensorflow. No Colab da seção já está definido para usar essa versão, basta executar os comandos na ordem https://colab.research.google.com/drive/1u32bsDb9M8ir2VaZvkOyUfJJV3v6OEML
Eu acabei de testar aqui e está funcionando, mas caso encontre algum problema é só avisar
Importante: Execute todos os blocos de código na ordem. Ao chegar na seção “Importação das bibliotecas” desse Colab, reinicie a sessão antes de fazer os imports (ao executar o comando de instalação provavelmente já irá aparecer um botão no output da célula – ou, você pode reiniciar também selecionando a opção no menu do topo: ‘Ambiente de execução > Reiniciar sessão’)
Olá Damião,
Desmarquei aqui como concluído para você as aulas. Ao concluir a aula ou clicar no botão verde a aula é marcada como concluída, para que assim seu progresso fique salvo.
Sobre a seção não abrir, você poderia descrever o que acontece para você? O que aparece na tela, qual mensagem, e qual a URL que você está
Para você deveria estar aparecendo mais ou menos conforme esse print abaixo
Para retornar à aula 1, acesse o curso e clique sobre a seção/aula – ou clique aqui https://iaexpert.academy/topic/conteudo-do-curso-17/
Olá Vinícius! Na verdade o Colab está na aba “Materiais” da primeira aula onde aquele conteúdo do Colab começa a ser mostrado (que é onde o código da seção começa a ser desenvolvido).
Por exemplo: para a primeira seção (DCGAN e WGAN) o código Colab começa a ser construído na aula Base de dados MNIST. Portanto, o código completo desenvolvido estará na aba ‘Materiais’ dessa aula. Imagino que tenha verificado apenas a primeira aula da seção (onde mostra somente a parte teórica – ou seja, ainda não começou a mostrar o código). Para evitar essa confusão, já alteramos a descrição dessa aula onde você viu essa mensagem.
Olá Edjander!
Realmente precisa esperar a autorização deles para usar com essa implementação do Hugging Face, mas enquanto isso você pode usar outros modelos que não precisam autorização (como o Phi, mostrado no curso) ou até tentar pedir a autorização de outros modelos. Ou também dar uma olhada na lista de modelos (alguns não pedem autorização), veja aqui https://huggingface.co/models?sort=trending&search=llama
Outra solução boa é usar o modelo através do provedor Groq, lá tem as versões modernas do Llama e outros (como o DeepSeek) sem precisar essa autorização da empresa.
Para fazer isso, precisará instalar a biblioteca com !pip install langchain-groq e em seguida, fazer o import com from langchain_groq import ChatGroq
Isso é explicado com detalhes nessa aula “Conexão com a LLM“, que faz parte do curso LLMs e Agentes de IA para Empresas e Negócios. Basta fazer a importação do lanchain-groq e seguir exatamente como mostra essa aula.
Obs: ali nessa aula é mostrado o modelo ‘llama3-70b-8192’, mas para acessar a versão mais moderna basta mudar de ‘llama3-70b-8192’ para ‘llama-3.3-70b-versatile’ (ou se quiser pode trocar por outra, como Llama 4 ou DeepSeek pro exemplo)
– você pode conferir todos os modelos disponíveis no plano gratuito nessa página aqui: https://console.groq.com/docs/rate-limits-
This reply was modified 3 months, 2 weeks ago by Gabriel Alves.
Olá Vladimir!
Isso mesmo, ótimo ponto. O NotebookLM não treina o modelo com dados enviados, o que acaba protegendo a privacidade mas também porque evita esse “envenenamento de dados”. Portanto usa os documentos apenas como contexto isolado, sem incorporá-los ao modelo base, uma decisão coerente do ponto de vista de governança e gestão de risco devido aos pontos que você comentou.
Obrigado pela contribuição!
Olá Douglas! Usar um modelo multimodal (como o Gemini que usamos na aula) dá para automatizar sim esse processo para auxiliar operadores a identificar possíveis objetos ilícitos em imagens de scanner corporal, porém é importante entender que esses modelos foram treinados principalmente em imagens “naturais” da internet e dados médicos genéricos, não em bases específicas de scanners corporais. Isso significa que, fora do domínio médico tradicional (raio-X clínico, TC, RM), a performance pode cair bastante, especialmente para objetos pequenos, sobrepostos ou com baixa diferenciação de densidade. Para algo mais confiável, o ideal seria treinar um modelo usando dataset próprio do scanner real (com fotografias de casos próximos ao que o modelo irá detectar), para isso usando imagens rotuladas por especialistas e métricas de validação estatística (precisão, recall, falsos positivos/negativos), testes em ambiente controlado e, se possível, fine-tuning ou pelo menos fazer uma avaliação sistemática por tipo de objeto.
Quanto aos riscos que você perguntou, os principais são: falsos negativos (o modelo deixa passar algo ilícito), falsos positivos (gera alertas desnecessários), viés do conjunto de testes (imagens da internet não representam o mundo real).
Caso deseje construir uma aplicação assim, garanta que use uma pipeline consistente (fazer o pré-processamento da imagem sempre igual e usando técnicas), logs de inferência (para poder validar e checar depois caso dê algum problema), e monitoramento contínuo e fallback humano.
Seja para essa abordagem apresentada no curso ou outra similar, o mais correto é tratar o sistema como suporte da decisão para o operador do scanner: ele sugere, o agente decide. Também vale envolver jurídico/gestão desde cedo, porque isso entra em segurança pública e pode exigir homologação, auditoria e políticas claras de uso.
Por fim, lembre-se de um ponto essencial: LLMs e modelos multimodais estimam padrões, eles não “sabem” o que estão vendo na realidade. Portanto, nunca trate a resposta como verdade absoluta; use apenas como apoio à decisão humana, com validação contínua em campo. Mas quanto a essa questão de errar, até mesmo um profissional experiente da área pode cometer erros, portanto o aconselhável é testar o modelo com amostras reais para ver qual é a taxa de erro e a partir dessa taxa decidir se é aplicável na prática e se serve para essa função.
Olá Fernando!
Sim, foi mais complexo para fins de treinamento e exercitar a criação de queries maiores. O uso da tabela pedido_produto foi mais com propósito didático, para treinar subconsultas correlacionadas e agregações, do que por necessidade real do modelo. Em um cenário prático, se a coluna pedido.valor já representa corretamente o total do pedido, o mais simples (e correto) seria usá-la diretamente, sem recalcular nada.
E sua observação está correta sim, o exercício desconsidera a quantidade.
Pra levar em consideração a quantidade, você usaria desse modo:
sum(pdp.valor_unitario * pdp.quantidade)
Olá Eder! Lamento a confusão, o seu certificado foi gerado assim que você concluiu o curso mas talvez o botão de download não estivesse aparecendo pra você na hora, porém verifiquei aqui e agora já deve estar exibindo normalmente. Mandei mais detalhes no ticket que você criou.
Esse botão de download aparece na página do curso (estando logado em sua conta) ou a página “Meus cursos”.
Olá Joaquim!
Você está usando o modelo “llama3-70b-8192”, isso? (de acordo com a mensagem de erro que forneceu)
Esse modelo foi recentemente descontinuado, portanto substitua pelo “llama-3.3-70b-versatile” ou o “llama-4-scout-17b-16e-instruct” por exemplo.
Outro modo de implementar o modelo groq é assim:
os.environ["GROQ_API_KEY"] = getpass.getpass("Groq API key: ") from langchain_groq import ChatGroq def load_llm(id_model, temperature): llm = ChatGroq( model=id_model, temperature=temperature, max_tokens=None, timeout=None, max_retries=2, ) return llm id_model = "groq/meta-llama/llama-3.3-70b-versatile" temperature = 0.7 groq = load_llm(id_model, temperature)-
This reply was modified 5 months, 3 weeks ago by Gabriel Alves.
16 de janeiro de 2026 at 00:31 in reply to: Erro com a Crew (Limite de requisições da API excedido) #52892Opa que bom que conseguiu resolver! E obrigado por comentar como resolveu, pois essa questão de precisar configurar o faturamento realmente não deveria causar esse erro
13 de janeiro de 2026 at 21:06 in reply to: Ajuda na Aula “Instalação das ferramentas (Tabelas e consultas)” #52855Olá Rafael!
Após fazer o download do instalador (arquivo .exe) você deve apenas prosseguir com as etapas de instalação de forma normal, não precisa mudar nenhuma opção, basta clicar para prosseguir e o sistema automaticamente vai fazer tudo.
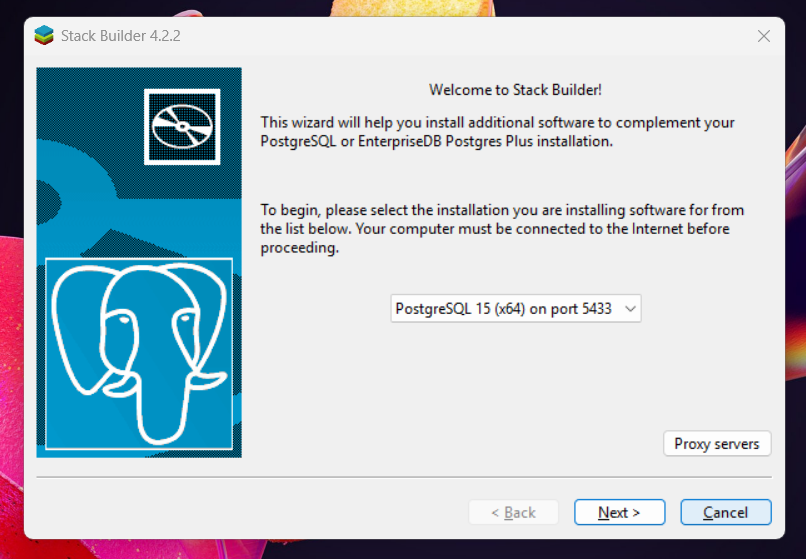
Pelas opções que você descreveu, essa parte que você se refere seria o Stack Builder (conforme nesse print abaixo), confere? É normal essa janela aparecer automático logo após a instalação.
Aqui você pode clicar em Cancel quando chegar nessa parte, basta ignorar pois não é necessário (é usado para instalar outras extensões complementares, que não são necessárias pro curso).
 12 de janeiro de 2026 at 20:10 in reply to: Erro com a Crew (Limite de requisições da API excedido) #52849
12 de janeiro de 2026 at 20:10 in reply to: Erro com a Crew (Limite de requisições da API excedido) #52849Olá Joaquim!
Parece que o Gemini 2.5 Flash está executando melhor que o 2.0, vi alguns relatos recentes dizendo que o modelo 2.0 está recentemente exibindo essa mesma mensagem mesmo sem ter ultrapassado a quota.
Sugiro portanto trocar o modelo carregado, de “gemini/gemini-2.0-flash” para “gemini/gemini-2.5-flash”
Se mesmo assim o problema continuar, uma outra forma de resolver é alterar o max_rpm (dentro da Crew) para um valor menor (ex: 10). Se você fizer essa mudança, precisa reexecutar todos os blocos na ordem
Com isso deve resolver, mas se mesmo assim não der então daria pra tentar criar a chave em outra conta Google. Essa sua conta pode estar com alguma restrição de algum modo, então teria que rever as configurações e permissões. Mas nesse caso, para ser mais rápido e eliminar essa possibilidade, eu recomendaria gerar essa chave com outra conta google/gmail
Olá Augusto!
Após executar esse comando, execute wsl –version e verifique se a versão foi alterada ou não, pois pode ser que após executar o comando tenha aparecido uma mensagem dizendo que foi atualizado mas na verdade não foi (isso é um problema relativamente comum).
Se persistir o problema, recomendo seguir as recomendações desse vídeo.
Outra forma é desabilitar as opções ‘Windows Subsystem for Linux’ e ‘Virtual Machine Platform’ dentro de ‘Turn Windows Features on or off’ (mostrado no vídeo), reiniciar o PC, e depois habilitar novamente. Em seguida, execute o comando wsl –install
Em último caso, dá para tentar instalar manualmente (link aqui)
-
AuthorPosts