
Um desafio clássico para a ciência da computação foi a habilidade de processar linguagem natural. Isso ocorreu porque computadores só entendem números, mas a estrutura das línguas é muito mais complexa do que a matemática. Nós mesmos não pensamos as palavras e suas relações de forma explicitamente numérica, mas sim intuitivamente.
Nas últimas décadas, várias técnicas avançaram tentando cobrir esse terreno. A eficiência pode ser comprovada pela forma impressionantemente natural com que algumas ferramentas se expressam. Como isso foi possível?
Uma das ferramentas mais populares é a técnica chamada de word embedding. A ideia é transformar as palavras em números, mas não só isso: de alguma forma, as relações entre as palavras têm que ser mantidas.
O processo deve partir de um corpus: um conjunto de textos da onde as relações serão aprendidas. Para explicar o princípio, vamos usar um pequeno exemplo. Nosso corpus é composto da seguinte frase:
O carro vermelho atingiu o caminhão azul.A maneira mais básica de transformar esse corpus em números é separar o texto em palavras, construir uma tabela quadrada onde cada linha corresponde a uma palavra e cada coluna corresponde a uma dimensão, que no caso correspondem às palavras contidas no corpus, e codificar se a palavra existe ou não naquela dimensão. Assim:
Palavras = (atingiu, azul, caminhão, carro, o, vermelho)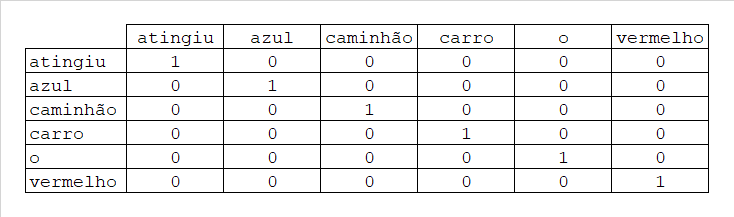
Dessa forma, cada palavra pode ser representada por um vetor multidimensional contendo os valores correspondentes à sua linha:
atingiu = [1, 0, 0, 0, 0, 0]
azul = [0, 1, 0, 0, 0, 0]
caminhão = [0, 0, 1, 0, 0, 0]
carro = [0, 0, 0, 1, 0, 0]
o = [0, 0, 0, 0, 1, 0]
vermelho = [0, 0, 0, 0, 0, 1]Essa primeira abordagem apresenta dois problemas:
- A representação tende a ser enorme, já que vamos ter tantas dimensões quanto palavras contidas no corpus.
- Não é possível estabelecer relações entre as palavras. Cada palavra está isolada em sua própria dimensão.
O word embedding busca justamente resolver esses pontos fracos. Como?
Da análise morfológica do nosso corpus, nós notamos que temos artigos (o), substantivos (carro, caminhão), adjetivos (azul, vermelho) e verbos (atingiu). Dessa forma, nós poderíamos representar esse corpus ao longo de uma única dimensão morfologia:

Observe que eu também codifiquei as categorias morfológicas com números. Assim, eu posso representar as palavras originais ao longo dessa dimensão:
atingiu = [4]
azul = [3]
caminhão = [2]
carro = [2]
o = [1]
vermelho = [3]Só que, de acordo com essa representação, caminhão e carro são a mesma coisa (2), assim como azul e vermelho (3).
Mas eu posso repetir o processo considerando uma outra dimensão para separar esses casos! Vamos criar a dimensão tamanho.
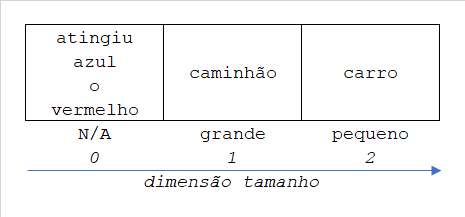
Algumas palavras não podem ser separadas por tamanho, por isso eu indiquei N/A (não se aplica) e coloquei elas na posição 0. A nova representação das palavras, agora num espaço bidimensional, fica:
atingiu = [4, 0]
azul = [3, 0]
caminhão = [2, 1]
carro = [2, 2]
o = [1, 0]
vermelho = [3, 0]Ainda precisamos separar azul de vermelho. Vamos criar a dimensão cor.
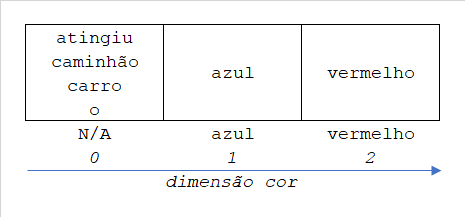
A interpretação é parecida com a situação anterior. Mas observe que eu estou classificando as palavras livres de contexto, não dentro da interpretação fornecida pelo corpus. Por isso, não estou colocando carro na categoria vermelho nem caminhão na categoria azul.
As palavras nessa representação tridimensional ficam:
atingiu = [4, 0, 0]
azul = [3, 0, 1]
caminhão = [2, 1, 0]
carro = [2, 2, 0]
o = [1, 0, 0]
vermelho = [3, 0, 2]Agora, toda coordenada nesse espaço representa um único conceito. Observe que nós conseguimos fazer isso em apenas 3 dimensões, ao invés das 6 inicialmente propostas.
Outra grande vantagem é que pontos mais próximos nesse espaço tridimensional representam conceitos similares. Por exemplo, a distância entre caminhão e carro é de apenas 1, enquanto caminhão e azul é 3.
Finalmente, nós podemos fazer operações matemáticas em cima dessas representações. Por exemplo, o vetor t = [0, 1, 0] representa um movimento para a direita na dimensão tamanho. Dessa forma, caminhão + t = carro.
Nesse exemplo nós usamos a intuição para separar as palavras em dimensões, mas para a aplicação do conceito em inteligência artificial, geralmente recorremos a modelos baseados em deep learning. O modelo busca classificar uma palavra ao longo das dimensões com base no seu contexto, ou seja, nas palavras que a antecedem ou procedem. A natureza das dimensões, por sua vez, é definida por lógica matemática, e dependendo do número de dimensões (camadas ocultas) que usamos, seu significado nem sempre é compreensível. As representações e associações tendem a ser mais eficientes quanto maior for o corpus de referência, de forma que, em teoria, um corpus infinito usado para treinar um modelo à exaustão seria capaz de entender as relações linguísticas com perfeição.
A inteligência artificial no campo da linguagem natural avança a passos largos. Em breve seremos incapazes de distinguir um discurso gerado por uma pessoa ou por uma máquina!
Legal, Denny! Super didático. Parabéns 🙂
Alex Camargo
Bioinformata
Que bom que gostou do artigo Alex 🙂
Top demais
Que bom que gostou Samuel 🙂
Muito didático!
Parabéns pele artigo e pelo compartilhamento!
Que bom que gostou Anderson 🙂
Valeu Denny. Estou iniciando estudos na área IA para análise de textos.
Muito bem explicado, tinha um pouco de entender as Words Embeddings