
Redes neurais são eficientes porque elas encontram padrões no meio de ruído. Decompondo as informações contidas nos dados em partes elementais, elas conseguem identificar as partes que se repetem de forma lógica, e assim chegar a decisões sobre os dados a que são apresentadas. É assim que funcionam classificadores de imagens, analisadores de sentimento ou transcritores de voz.
Entretanto, esse processo não é transparente. Muitas vezes é difícil, se não impossível, compreender como a rede neural toma suas decisões. Determinada camada escondida pode estar claramente interpretando curvas num desenho ou tons graves num discurso, mas em muitos casos as características da camada são misteriosas, pois elas extraem padrões que fogem à nossa habilidade de discernimento. O problema se acentua conforme o modelo vai ficando mais preciso em suas predições, pois mais “padrões invisíveis” são reconhecidos.
Entretanto, conforme vamos habilitando a inteligência artificial a tomar decisões mais importantes – como dirigir nossos carros ou fazer nossas decisões médicas – essa transparência se torna essencial. E se a rede neural estiver nos indicando um tratamento que vai nos curar no curto prazo (pois foi isso que lhe foi solicitado), mas fará a doença piorar no médio? Como é difícil predizer todas essas possíveis situações para imbuir os modelos de machine learning com todos os dados necessários, a alternativa é entender a racionalização por trás da decisão.
Com isso em mente, uma equipe do Instituto de Tecnologia de Massachusetts (MIT) desenvolveu um modelo para gerar racionalizações de decisões neurais. O modelo tem por objetivo extrair um subconjunto dos dados de entrada que possa ser qualificado como racionalização da predição feita pela rede. Uma racionalização deve atender a dois critérios: deve ser interpretável, ou seja, não adianta extrair palavras soltas e desconexas de um conjunto de textos por exemplo, essas palavras devem estar numa frase que tenha sentido; e deve ser capaz de chegar às mesmas conclusões que os dados originais. Em outras palavras, uma racionalização deve ser curta e suficiente. Mais ou menos como justificamos nossas próprias decisões.
O modelo desenvolvido é composto de duas partes. A primeira, chamada de codificador, que pode ser na forma de uma rede neural recorrente, fica responsável pela predição, seja baseada nos dados originais, seja baseada no subconjunto. A segunda, chamada de gerador, que também pode ser uma rede neural recorrente, é quem gera as possíveis racionalizações. As duas partes são ligadas por duas funções de custo: uma garante que as racionalizações sejam curtas e compreensíveis, a outra garante que as racionalizações são suficientes para chegar às mesmas decisões.
O modelo foi testado utilizando um banco de dados que contém 1,5 milhão de reviews de cervejas escritos por usuários na internet. Esses reviews cobrem naturalmente vários aspectos de qualidade, seja o aspecto geral, seja características como aparência, aroma, paladar ou sabor. Cada review também contém uma nota dada pelo usuário, que serve como variável de saída do modelo. A qualidade das racionalizações geradas pelo modelo foi comparada com um banco de dados de teste curado manualmente. Na avaliação de aparência e aroma, a escolha de racionalizações chegou a precisões acima de 95%. Na avaliação de paladar, ultrapassou 80%.
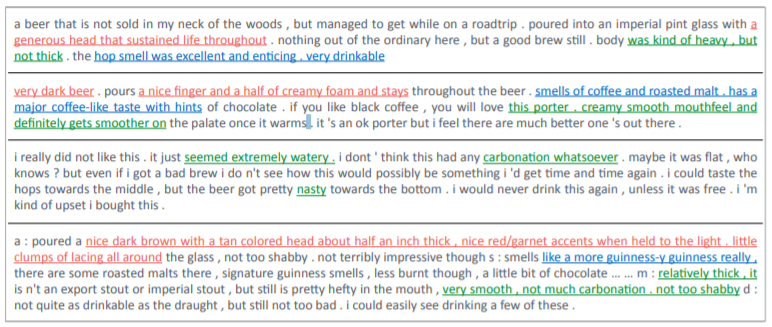
O trabalho é uma importante evolução na interpretabilidade de redes neurais. Em breve, seremos capazes de perguntar à inteligência artificial não só “qual”, mas também “por quê”. Uma importante garantia para que nossos interesses continuem alinhados.