
Quando nós estamos falando com alguém ao telefone, automaticamente construímos um modelo mental de como a pessoa se parece. Algumas características são mais fáceis de prever a partir da voz, como o gênero e a idade aproximada da pessoa, mas atributos secundários como o sotaque também podem nos indicar sua origem, que costuma estar correlacionada com a aparência predominante daquela população. Tendo isso em vista, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL) do Instituto de Tecnologia de Massachusetts (MIT) publicaram em maio seu trabalho onde usaram redes neurais profundas para prever a fisionomia facial de pessoas a partir de sua voz.
O trabalho parte do pressuposto de que algumas características da voz são correlacionadas com atributos de aparência como idade, gênero, o formato da boca, a estrutura dos ossos faciais, e a espessura dos lábios; além disso, o idioma, o sotaque, a velocidade e a pronúncia costumam ser compartilhadas entre nacionalidades e culturas, que também podem indicar atributos físicos em comum. Dessa forma, os pesquisadores quiseram verificar em que extensão é possível inferir a aparência de uma pessoa a partir da forma como ela fala. Ainda que a correlação entre voz e aparência não seja exata, o objetivo era predizer traços faciais dominantes a partir de pequenos segmentos de áudio.
Para tanto, o trabalho usou o banco de dados AVSpeech, que contém milhões de vídeos de mais de 100.000 pessoas diferentes publicamente disponíveis no YouTube. Os vídeos são primeiro decompostos para formar um par voz/face. As imagens então passam por uma rede neural pré-treinada, chamada de modelo VGG-Face, para classificar faces. Esse modelo produz vetores contendo informação suficiente para representar os atributos de rostos em uma dimensão menor que a original. A penúltima camada dessa rede (aquela logo antes da camada de classificação), contendo 4.096 variáveis, é extraída para representar o rosto. Em paralelo, o espectrograma correspondente ao áudio é passado através de uma rede neural convolucional do tipo encoder, batizada de modelo Speech2Face pelos pesquisadores, e sua saída é comparada com o vetor do rosto para controlar as perdas e manter a correlação alta. Assim, todo o treinamento ocorre de forma auto-supervisionada, ou seja, sem a necessidade de anotação humana, uma novidade quando comparada com abordagens com o mesmo objetivo. Uma vez treinado, o modelo Speech2Face produz vetores de voz que podem ser alimentados para um decoder de faces, que faz a reconstrução do rosto em uma forma canônica (de frente, com expressão neutra).
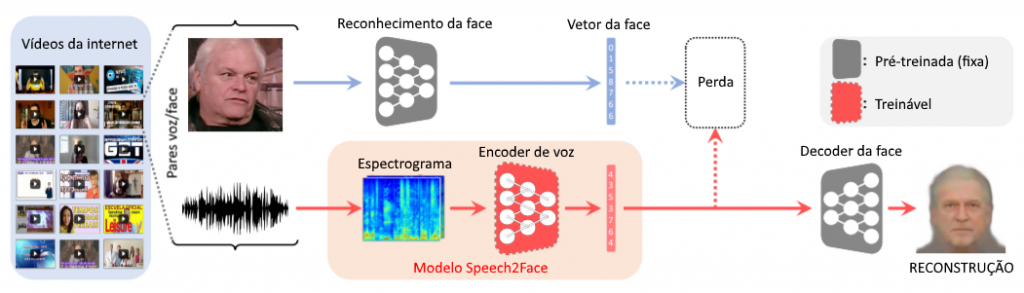
Para avaliar o desempenho do modelo Speech2Face, os autores do trabalho usaram o serviço Face++ para definir atributos como gênero, idade e etnia, tanto às imagens usadas na pesquisa quanto às imagens reconstruídas. Como resultado, a correlação entre os gêneros foi alta, tendo precisão de 94%. As correlações entre as idades também foram altas, chegando na faixa de 38% para correspondências exatas. No quesito etnia, o modelo desempenhou melhor na reconstrução de rostos de locutores brancos e asiáticos, tendo dificuldade em classificar corretamente negros e indianos, o que pode ser um reflexo de essas etnias estarem sub-representadas no banco de dados usado.

Adaptado do artigo original.
Com seu trabalho, os autores dizem ter validado visualmente a existência de informação biométrica cross-modal, postulada em estudos anteriores. Eles esperam que a geração de faces a partir da voz, em contraposição à predição de atributos específicos, possa proporcionar uma melhor compreensão das correlações entre voz e face, abrindo novas oportunidades para pesquisa e aplicações.
EXCELENTE VISÃO, PARABÉNS PELO TRABALHO. SUCESSO EM NOVOS DESAFIOS.. GO AHEAD
Valeu Waldir! 🙂