
À medida que novos modelos de machine learning são desenvolvidos, os ganhos em desempenho têm aumentado significativamente. Entretanto, se os modelos mais complexos têm servido à tarefa de fazer classificações e predições precisas, esse resultado tem se dado às custas de sua interpretabilidade. Pode ser impossível, ou ao menos muito pouco intuitivo, entender como funciona internamente uma rede neural, por exemplo. Mas como a inteligência artificial tem invadido nossas vidas ao ponto de ficar responsável por decisões cruciais que devem ser guiadas por nossos princípios éticos – como aquelas que logo um veículo autônomo terá que tomar em situações onde há risco inevitável de dano a pessoas -, esse entendimento se torna indispensável.
Uma das principais razões para a dificuldade em interpretar os modelos de machine learning é que eles operam em características que não correspondem a conceitos mais gerais que os humanos desenvolveram ao longo da evolução. Por mais que nosso cérebro também opere primariamente em unidades mais básicas de informação (como os contornos e contrastes que um classificador de imagens também identifica), o que chega ao nível da consciência – e guia nossas decisões – é o conceito que emerge da soma de várias dessas unidades (como o nome do objeto para o qual estamos olhando). Da mesma forma que nos parece inútil saber quais neurônios do cérebro estão sendo ativados individualmente quando olhamos um tal objeto, os valores internos de uma rede neural – seus pesos e ativações – também nos parecem incompreensíveis.
Um trabalho publicado ano passado por pesquisadores do Google Brain propõe uma solução para o problema da interpretabilidade. Eles apresentam a noção de vetor de ativação de conceito (concept activation vector, CAV) como forma de traduzir o estado de uma rede neural para conceitos humanos interpretáveis. A ideia é treinar um modelo usando instâncias do conceito que se quer apreender (por exemplo, imagens básicas de listras) e contraexemplos aleatórios (imagens que não contenham listras). O CAV é definido como o vetor ortogonal à fronteira de decisão do modelo. Depois, o CAV é usado num método quantitativo chamado de Testing with CAV (TCAV), que usa derivadas direcionais para quantificar a sensibilidade do modelo de predição ao conceito em questão. O método é capaz de traduzir em um número, por exemplo, quanto o conceito de ‘listra’ foi relevante para classificar uma imagem como ‘zebra’.
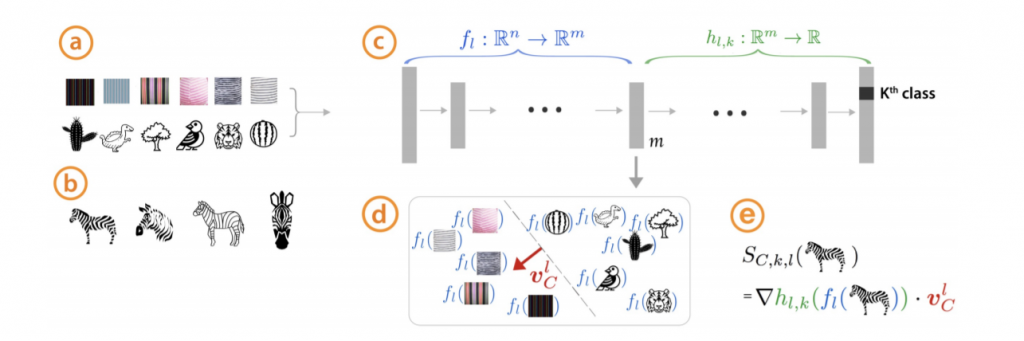
Fonte: artigo original.
A figura abaixo mostra alguns resultados, representados por valores de sensibilidade, através das camadas da rede neural GoogleNet. Observa-se que, no caso do motor de combustão (gráfico da esquerda), as camadas são geralmente mais sensíveis para o conceito vermelho, que inclusive é máximo na última camada, o que indica alta relevância do conceito na definição da classe. Esse resultado corresponde à nossa intuição. A classe zebra (gráfico da direita) também é mais sensível, em camadas intermediárias da rede, para o conceito listrado, e depois zigue-zague.
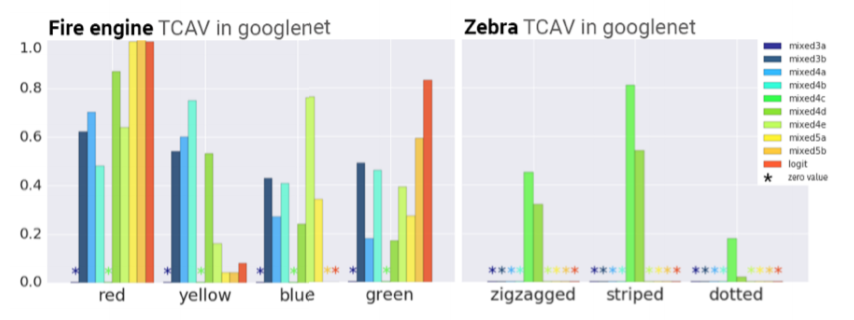
O trabalho também demonstrou que a alta sensibilidade a conceitos mais simples, como cores, costuma ocorrer logo nas primeiras camadas; conceitos mais complexos só são apreendidos em camadas mais profundas. Essa verificação está de acordo com a noção de que as primeiras camadas das redes neurais funcionam como detectores de características básicas (como contornos), enquanto que as camadas posteriores detectam características mais complexas (como classes).
A possibilidade de interpretar as decisões de modelos de machine learning é essencial para seu uso responsável. O método TCAV auxilia na interpretação do estado interno de redes neurais profundas, tornando possível entender as decisões do modelo em termos de conceitos naturais. Os conceitos não precisam ser conhecidos no instante do treinamento, podendo ser facilmente especificados numa análise posterior, o que expande sua aplicabilidade. Ainda que seu desenvolvimento inicial tenha usado apenas imagens, o método não é limitado a esse formato, podendo ser aplicado para outros tipos de dados como áudio e vídeo. Novos desenvolvimentos podem inclusive torná-lo apto a identificar conceitos automaticamente.