O imageamento por ressonância magnética (MRI, magnetic resonance imaging) é atualmente um método muito utilizado para o diagnóstico de doenças, já que é capaz de revelar em detalhes estruturas de tecidos e órgãos. Entretanto, fatores como o ruído no sinal, que é inerente dos equipamentos, contribuem para limitar a resolução e a qualidade das imagens obtidas. O MRI possui resolução na casa dos milímetros, devido às propriedades magnéticas dos tecidos e variando em função da forma com que o sinal e o ruído são obtidos e filtrados. Essa resolução é limitada por fatores como o tempo de aquisição e os movimentos do paciente dentro do equipamento.
Uma das formas de melhorar os resultados é o processo chamado de super-resolução (SR, super-resolution), onde uma imagem de baixa resolução é melhorada através de técnicas de pós-processamento. Nesse sentido, pesquisadores da Universidade de Málaga, na Espanha, publicaram ano passado um trabalho onde eles usam uma estrutura de rede neural convolucional 3D para fazer esse trabalho, sem distorcer as estruturas dos tecidos capturados na imagem. A ideia básica é capturar imagens em baixa resolução com deslocamento em intervalos regulares (por exemplo, cortes com espaçamento de alguns milímetros entre si) e submetê-las à rede, que faz a reconstrução das imagens num espaço de maior resolução. Depois, essas imagens são ajustadas em função dos deslocamentos iniciais, e usadas para reconstruir a imagem original com resolução aumentada. O algoritmo foi testado usando sete imagens de diferentes datasets, para atestar sua robustez.
Os resultados obtidos mostram uma melhora considerável no processo de super-resolução em comparação com outros nove métodos disponíveis, e quantitativamente comparáveis com a mesma imagem obtida em alta resolução, sem aumentar excessivamente o tempo computacional. Com o hardware utilizado, de características top de linha no mercado para consumidor doméstico, o equipamento levou 3-4 minutos para processar uma imagem.
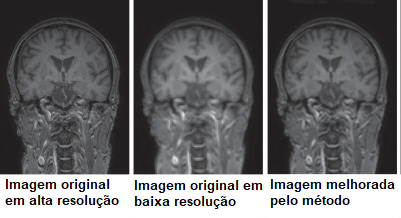
Uma das vantagens de usar um método baseado em inteligência artificial para aumentar a resolução das imagens é que o processamento não precisa ser supervisionado, ou seja, essa etapa ocorre sem presença humana. Outra, de ordem prática para o paciente, é que ele precisa ficar menos tempo imobilizado na máquina, já que esse processamento é realizado todo após a aquisição. Como atualmente uma captura pode levar até cerca de 30 minutos em condições de imobilidade e confinamento, o sucesso do método desenvolvido deve representar um aumento no conforto de quem se submete ao exame.
Excelente!!