
Na última postagem, eu tratei do mecanismo de atenção, que é a base sobre a qual a estrutura do transformer se sustenta, e que garante sua alta eficiência em tarefas do tipo seq2seq, ou seja, aquelas que recebem uma sequência e produzem outra, seja uma tradução em outro idioma, um sumário ou a legenda de uma imagem. Neste texto, vou explicar como o conceito da atenção é implementado na arquitetura do transformer, que é bem diferente daquela das redes neurais recorrentes (RNNs) demonstradas no texto anterior.
O transformer foi apresentado no artigo Attention is All You Need, título que deixa claro o papel central da atenção neste modelo. Assim como nas redes tratadas no artigo anterior, o transformer também apresenta dois módulos, o encoder e o decoder; no artigo mencionado, os autores construíram cada módulo como 6 stacks de encoders/decoders individuais arranjados linearmente. Cada encoder dentro de um stack é composto por duas unidades: uma chamada de self-attention, que aplica o mecanismo de atenção sobre o texto que ela recebe, e outra do tipo feed forward, que converte o resultado da camada de self-attention em um embedding de comprimento menor. O decoder é formado por essas mesmas unidades, mas entre elas há uma camada adicional chamada de encoder-decoder attention, que é quem mapeia o resultado da camada de self-attention do decoder com os embeddings produzidos pelo encoder.
Conheça o curso Processamento de Linguagem Natural com Deep Learning, que você aprende a implementar passo a passo a arquitetura Transformer para tradução de frases em Inglês para frases em Português!
Primeiro vamos tratar do processamento que ocorre no encoder. Diferente das RNNs onde as palavras são processadas em sequência, o encoder recebe o texto que ele deve processar de uma vez só, todas as palavras já convertidas em embeddings por um método independente. Na camada de self-attention, cada palavra é convertida em três vetores, chamados de query, key e value. Esta transformação é feita multiplicando o vetor da palavra por três matrizes, WQ, WK e WV respectivamente, que têm seus parâmetros ajustados durante o treinamento da rede. Estes novos vetores são meras abstrações que servem para permitir o cálculo de atenção. O vetor q da palavra-foco (por exemplo, a primeira palavra na sequência) é multiplicado (multiplicação vetorial) pelo vetor k de todas as palavras da sequência (inclusive a própria palavra-foco), o que produz um valor escalar para cada par de palavras, que indica um score. Este score é então dividido por 8 (pra ser específico, pela raiz quadrada do comprimento dos vetores key), o que garante maior estabilidade dos gradientes. Ao resultado de todo par é aplicada a transformação softmax, que resulta em valores no intervalo de 0 a 1, sendo que a soma de todos os valores é igual a 1. Este resultado representa um peso que determina quanta “atenção” a rede deve prestar a cada par de palavras, quando a palavra-foco estiver, bem, “em foco”. Agora, o valor do softmax é multiplicado pelo vetor v das palavras correspondentes (a palavra com que a palavra-foco faz par), e os resultados finais (vetores s) são somados, produzindo, finalmente, um vetor z para a palavra-foco, que incorpora as relações entre a palavra-foco e todas as palavras da sequência, com sua devida atenção considerada. A figura abaixo demonstra esta parte do processamento em um texto com duas palavras, onde a palavra 1 é a palavra-foco.
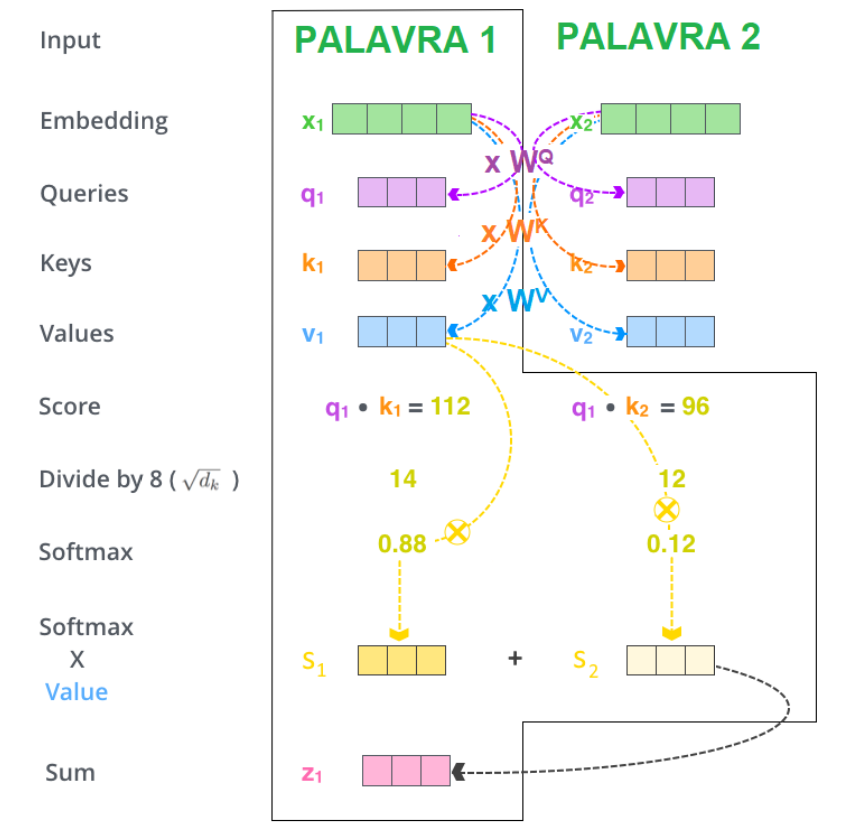
Os valores numéricos são ilustrativos. Observe que os vetores s estão em diferentes tons de amarelo para demonstrar o efeito de multiplicar o valor dos vetores v pelo softmax correspondente; é como se, nesse exemplo, s1 fosse acentuado em relação a s2, portanto terá maior peso na composição de z1.
É importante comentar que o encoder não realiza o mecanismo de atenção uma única vez. É só pensar que, quando nós estamos lendo um texto, não prestamos atenção em uma única parte, mas sim em várias partes ao mesmo tempo. Por exemplo, se estamos lendo um livro, temos que lembrar o nome do personagem, onde ele mora, com quem se relaciona, onde trabalha… O transformer também faz a mesma coisa. Para isso, ele não possui apenas uma chave de matrizes WQ, WK e WV, mas sim 8. Cada chave dessas é chamada de attention head, ou cabeça de atenção em uma tradução livre. Logo, no final da camada de self-attention, existem 8 vetores z para cada palavra do texto. A última etapa é concatenar estes vetores, e depois multiplicar o vetor resultante por uma matriz de pesos WO, que também é calibrada durante o treinamento do modelo. Como resultado, cada palavra volta a ser representada por um vetor z com o mesmo comprimento que o vetor v. Estes vetores agora podem passar para a unidade seguinte, aquela camada do tipo feed forward, para gerar os embeddings finais que indicam, no caso de uma tradução, a “ideia livre de idioma” que eu mencionei na postagem anterior.
O próximo passo é passar esses embeddings pelo módulo decoder. Primeiro eles são transformados em matrizes de atenção K e V, que serão usadas repetidamente em todas as camadas de encoder-decoder attention. O decoder começa seu trabalho aplicando a camada de self-attention no primeiro vetor que recebe, que indica o início da sequência traduzida, e faz o processamento da mesma forma que na camada de self-attention do encoder. Na camada de encoder-decoder attention, ele aplica as matrizes K e V mencionadas acima, que são produtos do processamento da sequência de entrada, ao invés de usar matrizes WK e WV ajustadas durante o treinamento. O resultado do stack que forma o decoder é, da mesma forma que no encoder, um embedding de comprimento igual ao do embedding que representa o texto original. Este embedding passa então por uma última camada linear, que o converte em um vetor de comprimento igual ao do vocabulário do segundo idioma, onde cada dimensão representa exatamente uma dessas palavras. Este vetor é ativado pela função softmax para se transformar em um vetor de probabilidades, e a posição com a maior probabilidade indica a palavra que o modelo deve, finalmente, produzir como saída. Ao retornar como resultado, esta palavra também volta a entrar no início do decoder, sendo usada para prever a segunda palavra, e assim por diante, até que o modelo produza um token que indica o final do texto.
Acompanhe o processo no vídeo abaixo.
Os transformers têm sido preferidos em relação às RNNs e mesmo LSTMs por dois motivos principais. Primeiro, como as palavras não precisam entrar na rede na sua sequência original, todas elas podem ser processadas ao mesmo tempo, o que permite a paralelização das operações e, por consequência, ganho de performance na velocidade. Segundo, o mecanismo de atenção é aplicado de forma muito eficiente, conseguindo manter as relações entre palavras relativamente distantes no texto, o que melhora a performance também no quesito precisão.
Este artigo não cobre todos os detalhes da estrutura do transformer: faltou explicitar, por exemplo, que antes de entrar no encoder, a todo embedding é adicionado um positional encoding (resultando no embedding with time signal que aparece do último vídeo), que serve para manter a relação temporal entre as palavras, ou seja, para que a rede saiba qual sua sequência original, e também não mencionei que existem camadas de adição/normalização após cada unidade de atenção e feed forward dentro dos módulos. Mas creio que a intuição básica por trás dessa estrutura tão potente e sofisticada tenha ficado clara.
Conheça o curso Processamento de Linguagem Natural com Deep Learning, que você aprende a implementar passo a passo a arquitetura Transformer para tradução de frases em Inglês para frases em Português!
Pingback: BERT, o modelo de processamento de linguagem natural que revolucionou a área – IA Expert
Excelente artigo! Parabéns
Que bom que gostou Denis 🙂