
Em machine learning, uma das formas mais clássicas de representar dados é na forma tabular, onde cada instância ocupa uma linha e cada feature, uma coluna; as instâncias são independentes entre si, então sua ordem geralmente não importa. Mas nem sempre é assim. Às vezes os dados possuem estruturas mais complexas, mantendo relações entre si que são relevantes para determinada tarefa. Pense, por exemplo, num banco de dados contendo os usuários de uma rede social. Além de features relacionados aos usuários que podem sim ser representados na forma tabular, nós temos conexões entre os usuários, que por sua vez, costumam ser representadas na forma de grafos mostrando quais usuários se relacionam com quais. Este nível de complexidade costuma ainda ser acompanhado pelo tamanho dos bancos de dados, já que um algoritmo de machine learning depende de uma quantidade elevada de instâncias para conseguir resolver problemas de difícil modelagem. Portanto, tanto complexidade estrutural quanto tamanho têm impacto direto na eficiência da solução que os métodos computacionais propõem. Nessa linha, entender sobre estrutura de dados é essencial para garantir que os algoritmos sejam eficientes, tanto em tempo de execução quanto em métricas de avaliação de desempenho.
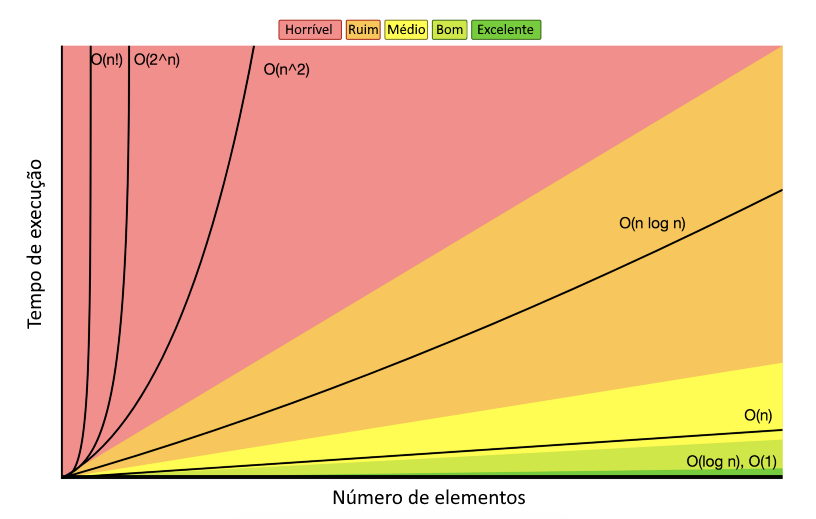
O tempo de execução de um algoritmo é representado na forma da chamada notação Big O. O(n), por exemplo, representa um algoritmo cujo tempo de execução escala linearmente em relação ao tamanho do banco de dados. É o caso de procurar um registro em uma lista desordenada; quanto maior a lista, maior – proporcionalmente – o tempo necessário. Alguns algoritmos podem não ser afetados pelo tamanho do banco de dados, tendo tempo de execução constante (O(1)); outros são drasticamente influenciados por este fator (O(n!)). Os tempos de execução mais comuns, do mais rápido ao mais lento, são:
O(log n) < O(n) < O(n log n) < O(n2) < O(n!)
O gráfico a seguir apresenta as relações entre tamanho do banco de dados e tempo de execução, com as regiões de interesse para um desenvolvedor de algoritmos.
Na sequência, apresentamos algumas das principais estruturas de dados, suas características e seu impacto na complexidade dos algoritmos onde são aplicadas.
Estruturas abstratas
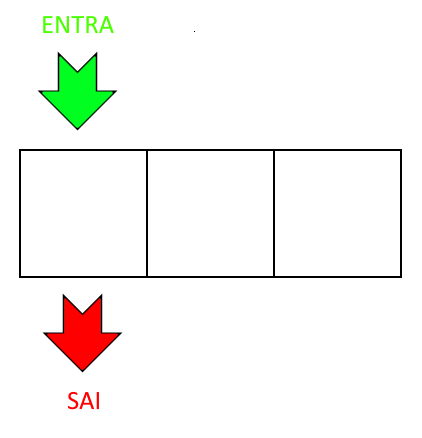
Pilha
Um jeito fácil de lembrar dessa estrutura é pensar numa pilha de pratos. A principal característica das pilhas pode ser deduzida do fato que o último prato que nós colocamos numa pilha é o primeiro que nós retiramos, e assim sucessivamente. Este método de armazenamento e acesso aos dados é chamado de last in first out (LIFO).
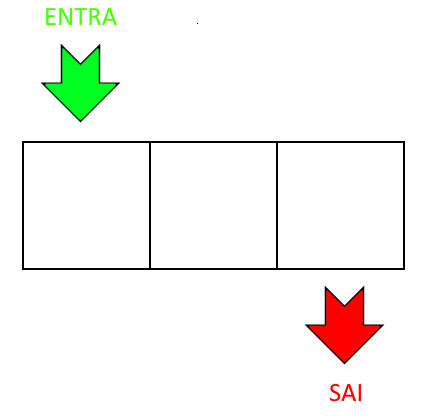
Fila
A fila também tem uma analogia fácil com uma fila de pessoas. Neste caso, a primeira pessoa que entrou na fila é a primeira que sai dela. Isto é chamado de first in first out (FIFO).
Estruturas concretas
Arrays
Os arrays são coleções lineares de itens, armazenados de forma contígua na memória. Todo elemento de um array possui um índice que indica sua localização. Na linguagem Python, a implementação dos arrays é conhecida como lista.
array = [value0, value1, value2, value3, value4]
# Para acessar valores:
In: array[0]
Out: value0Hash tables
Hash tables são as estruturas compostas por elementos que contêm, cada uma, uma chave e um valor. Os valores podem ser acessados a partir de sua chave correspondente. Em Python, sua implementação é o dicionário.
hash_table = {'key0': value0, 'key1': value1, 'key2': value2, 'key3': value3, 'key4': value4}
# Para acessar valores:
In: hash_table['key0']
Out: value0Grafos
Os grafos são dados que possuem conexões entre si. Cada elemento está contido em um nodo, e as conexões são chamadas de arestas. Existem grafos direcionados, onde as relações entre os nodos são unidirecionais, como por exemplo, na relação entre cliente e consumidor numa cadeia de produção; e grafos não-direcionados, onde não existe direção, como por exemplo, nos laços que indicam parentesco.

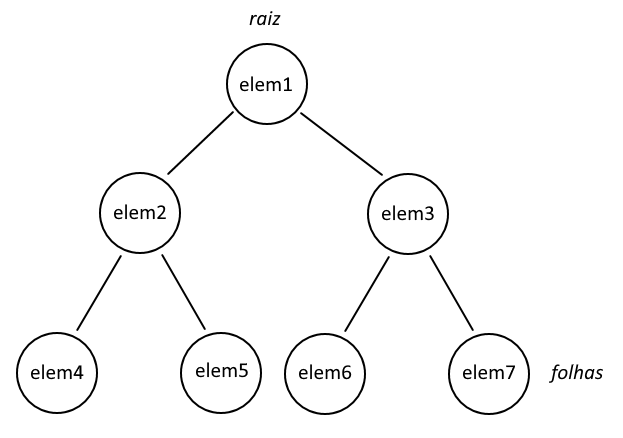
Árvores
Árvores são um tipo especial de grafo usado para representar hierarquia. Alguns exemplos são a árvore organizacional de empresas, e a árvore genealógica de famílias. Árvores tem uma origem, chamada de raiz, e terminações, chamadas de folhas. Só existe um único caminho entre a raiz e cada folha.
Impacto na complexidade computacional
Cada estrutura de dados possui um tempo de execução característico para acesso, busca, inserção ou deleção de elementos. Isso se deve à forma com que os elementos são ordenados e armazenados em memória, que afeta seu acesso e exige seu rearranjo caso sejam manipulados. A tabela abaixo sumariza a complexidade temporal para as estruturas apresentadas e algumas de suas derivações.
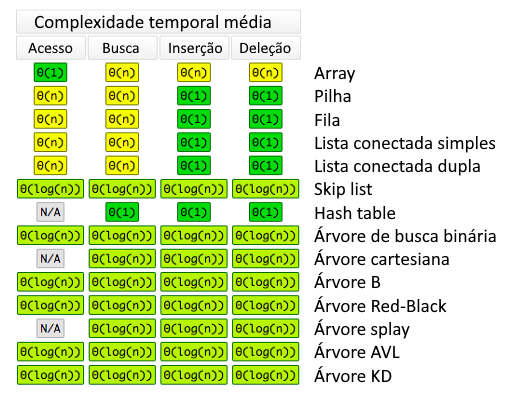
Este artigo apresentou as estruturas de dados básicas e explicou como elas afetam o desempenho de algoritmos de machine learning. O entendimento dessas relações nos ajuda a desenvolver algoritmos mais eficientes em questão de tempo e desempenho na tarefa que buscamos implementar.
Olá!
Legal esta reflexão e destacar o uso de estrutura de dados!
Parabéns!
Obs.: No trecho “Fila
A fila também tem uma analogia fácil com uma fila de pessoas. Neste caso, a primeira pessoa que entrou na fila é a primeira que sai dela. Isto é chamado de first in last out (FIFO).”
a parte final ficou errada o correto seria first in first out
Obrigado pelo comentário, Erlon. Tem razão quanto à informação, eu corrigi o texto, grato pela ajuda.