
As redes neurais são camadas de matrizes contendo valores de pesos e bias, que são inicializados de forma aleatória, e que são ajustados durante o treinamento para modelar o problema com que se está trabalhando. Basicamente, o que uma rede neural busca fazer é construir uma função que representa uma relação complexa entre as variáveis de entrada e as variáveis de saída, cuja modelagem puramente matemática seria muito difícil, se não impossível.
O papel dos pesos é determinar o impacto que o valor de cada variável de entrada tem no valor das variáveis de saída. Imagine, por exemplo, que um modelo esteja tentando estimar o preço de um carro com base em várias de suas características. Existe uma relação entre o preço e variáveis como a potência do motor, o número de portas, a quilometragem e o tempo decorrido do seu lançamento. Estas relações poderiam ser descritas na forma de uma equação linear:
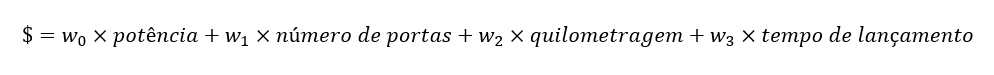
O tempo de lançamento, por exemplo, terá um impacto negativo no preço; quanto mais tempo decorrido, menor o valor. O peso w3 expressa justamente este impacto. Mas qual o valor do carro no lançamento, quando o tempo de lançamento é igual a zero? É justamente o valor do bias.

Para algumas variáveis, o bias não tem sentido prático (por exemplo, qual o valor do carro quando o número de portas é igual a zero?), mas matematicamente este conceito é necessário para expressar o resultado da variável de saída sem a influência da variável de entrada. Podemos pensar, por exemplo, em qual seria o valor de um carro sem portas, por mais que no mundo real tal carro não exista. O que importa é que, considerada a simplificação que estamos fazendo de uma relação linear, cada porta adicional terá um impacto constante no preço inicial teórico de um carro sem portas.
Nas redes neurais, o impacto do bias aparece de várias formas, que descrevemos a seguir.
Translação da rede neural
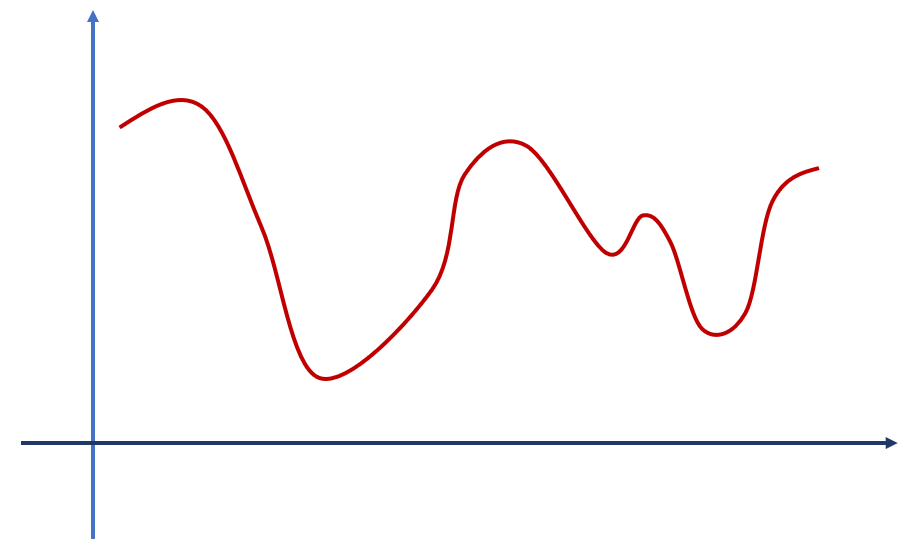
Voltemos à relação apresentada na primeira figura. Imagine que estamos buscando determiná-la com uma rede neural a partir dos dados incluídos como pontos verdes na figura abaixo.
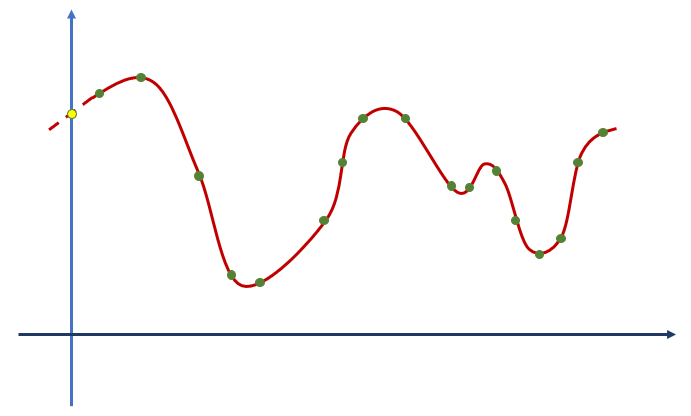
A disposição dos pontos verdes faz sugerir que este gráfico cruza o eixo y no ponto amarelo. Perceba, ainda, que neste ponto, x é igual a zero. Ou seja, o ponto amarelo indica o valor de y quando x é igual a zero. Este é exatamente o bias da equação representada pela curva vermelha. Sem a inclusão de um bias no treinamento da rede que fará a modelagem deste problema, a rede é forçada a incluir um ponto na posição (0, 0), resultando na figura abaixo.
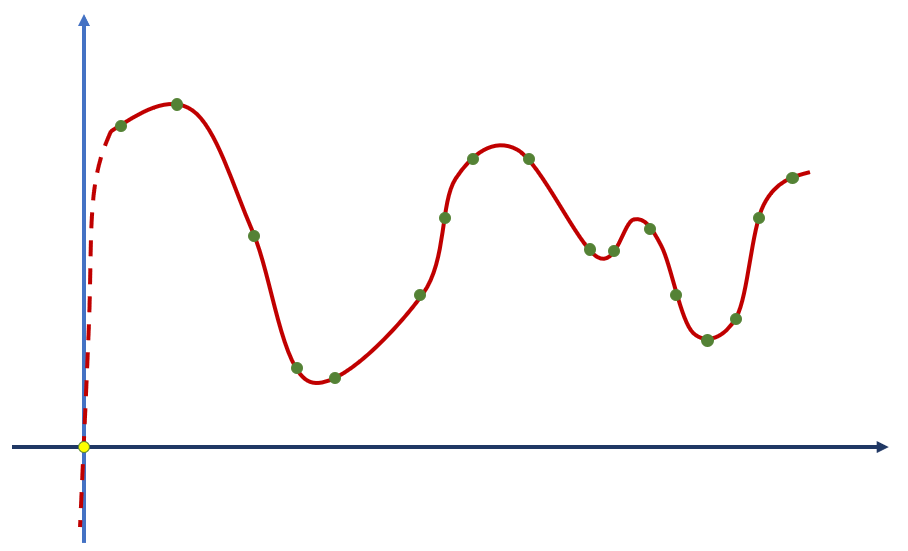
Esta não parece ser a solução ideal do problema, além de que claramente vai prejudicar o desempenho da rede neural na predição dos valores de y próximo a x = 0.
Em suma, o bias permite que a equação se desloque no gráfico, sem estar fixa ao ponto (0, 0). Em matemática cartesiana, esse deslocamento é chamado de translação.
Adiamento ou adiantamento de ativação
As funções de ativação são aplicadas logo após a saída de uma camada da rede neural, ou seja, após a multiplicação do valor em sua entrada pelo peso e o bias daquela camada. Usando como exemplo a função sigmoide, podemos observar que, sem um elemento de bias, a função de ativação também fica fixa no ponto (0, 0,5), como podemos ver abaixo:
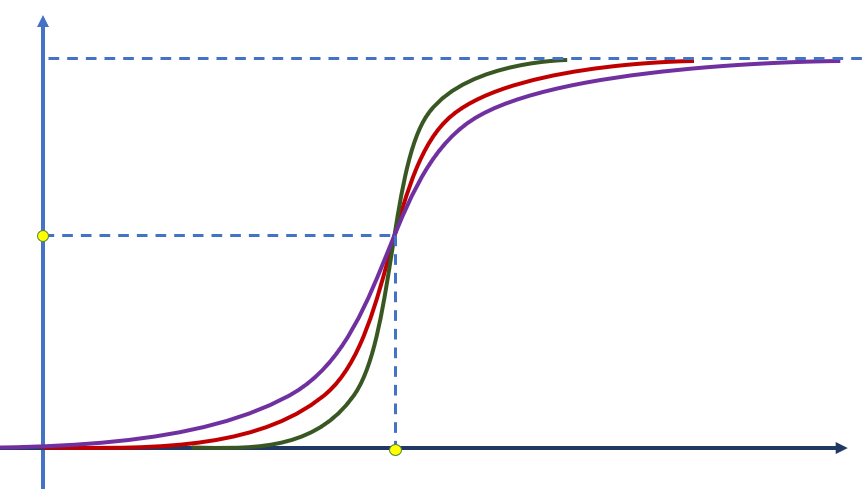
Com a introdução de bias, o gráfico da ativação também pode transladar, cujo efeito pode ser traduzido como um “adiamento” ou “adiantamento” da ativação: valores maiores ou menores de x vão produzir o mesmo efeito de ativação.
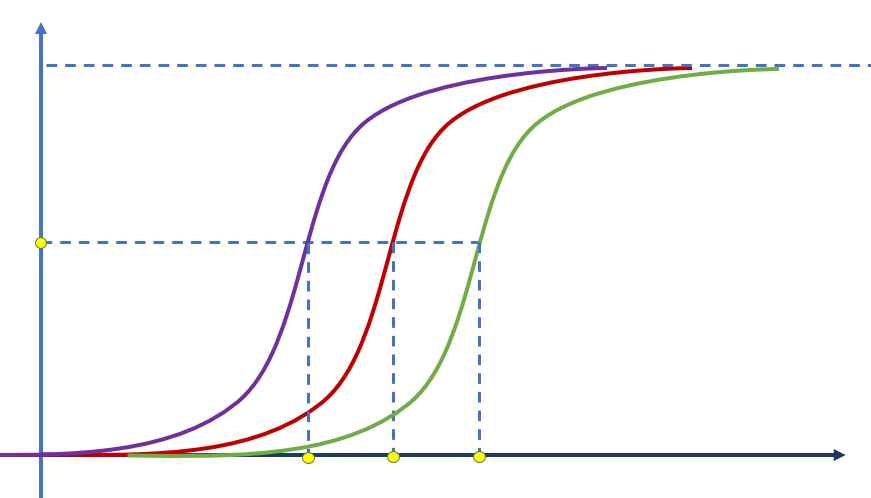
Capacidade de generalização
Quando uma rede neural sem bias está sendo treinada, o peso é ajustado para cada instância de dado que ela recebe, em função deste valor (lembre-se que o peso w é necessariamente multiplicado pelo dado x). Com isso, pode ser que a alteração induzida por uma instância anule a alteração provocada por uma instância anterior, e a rede tenha dificuldade para convergir para a melhor solução. Já que o valor do bias (b) é independente do valor do dado, ele “nivela” o processo de treinamento, fazendo com que as alterações nos pesos, induzidas pelas dados, sejam mais pontuais, menos dramáticas. O treinamento assim é mais estável, o que tem impacto positivo na convergência à solução ideal.
Quando usar bias?
Como vimos, a introdução de bias dá muito mais flexibilidade ao tipo de problema que uma rede neural é capaz de modelar. Entretanto, devemos nos lembrar que os valores de bias também serão ajustados durante o treinamento, o que tem um impacto computacional. Logo, se temos boas razões para dispensar o uso do bias, esta ação é justificável. É o caso de problemas onde temos certeza de que o valor zerado das variáveis de entrada resulta em variáveis de saída também zeradas, como, por exemplo, a relação entre o peso e a altura: obviamente que altura zero corresponde a peso zero. Mas se não temos condições de estabelecer esta premissa, é mais seguro incluir o bias, e deixar que o próprio processo de treinamento faça com que ele convirja para zero, se for o caso.
Parabéns pelo conteúdo.
Estou começando a estudar Machine Learning.
Que bom que gostou 🙂
Eu curti muito a explicação @Denny, como eu poderia citá-la em um trabalho?
Olá Felipe,
Sempre que possível, é mais recomendado citar um artigo científico ou um livro. Neste caso, você pode citar este livro que também foi publicado online: http://neuralnetworksanddeeplearning.com/
(No rodapé tem a forma de citação, e no capítulo 1 http://neuralnetworksanddeeplearning.com/chap1.html tem explicações sobre o bias.)