Home › Forums › Fórum Machine Learning e Data Science com Python de A à Z › Adicionar Novo Registro com Variável Categórica
- This topic has 10 replies, 3 voices, and was last updated 2 years, 2 months ago by
 Jones Granatyr.
Jones Granatyr.
-
AuthorPosts
-
22 de abril de 2021 at 19:41 #28440
Estava fazendo o Load do meu classificador da base de dados Census e ai gostaria de saber se há um modo alimentar o novo registro de forma categórica e fazer um tratamento para a entrega do resultado. Caso a maneira mais fácil seja a al realmente a alimentação númerica do novo registro, existe alguma função que correlaciona os dados categóricos da base original com os gerados no LabelEncoder?
Segue o código abaixo:
import pandas as pd import pickle from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np base = pd.read_csv('census.csv') previsores = base.iloc[:, 0:14].values classe = base.iloc[:, 14].values from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer labelencoder_previsores = LabelEncoder() previsores[:,1] = labelencoder_previsores.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores.fit_transform(previsores[:,5]) previsores[:,6] = labelencoder_previsores.fit_transform(previsores[:,6]) previsores[:,7] = labelencoder_previsores.fit_transform(previsores[:,7]) previsores[:,8] = labelencoder_previsores.fit_transform(previsores[:,8]) previsores[:,9] = labelencoder_previsores.fit_transform(previsores[:,9]) previsores[:,13] = labelencoder_previsores.fit_transform(previsores[:,13]) column_tranformer = ColumnTransformer([('one_hot_encoder', OneHotEncoder(), [1, 3, 5, 6, 7, 8, 9, 13])],remainder='passthrough') previsores = column_tranformer.fit_transform(previsores).toarray() labelencoder_classe = LabelEncoder() classe = labelencoder_classe.fit_transform(classe) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() previsores = scaler.fit_transform(previsores) mlp = pickle.load(open('mlp_final.sav', 'rb')) resultado_mlp = mlp.score(previsores, classe) novo_registro = [[39,'State-gov',77516,'Bachelor',13,'Never-married','Adm-clerical','Not-in-family','White','Male',2174,0,40,'United-States']] novo_registro = np.asarray(novo_registro)23 de abril de 2021 at 13:57 #28465Olá Nikolas, segue a resposta do instrutor Denny:
O novo registro deve primeiro passar por todo o processamento da mesma forma que o dataset usado no treinamento passou, ou seja, todas as etapas de LabelEncoder e o OneHotEncoder no final, mas desta vez usando o método transform já que fit é usado somente com os dados de treinamento. Entretanto, você precisa observar que, sempre que usa o método fit_transform na mesma instância do LabelEncoder (no caso, labelencoder_previsores), como foi mostrado na aula, ele perde a informação referente à variável que já havia processado. Para evitar isso, é preciso criar uma instância separada para cada variável, como por exemplo:
labelencoder_previsores_1 = LabelEncoder() labelencoder_previsores_3 = LabelEncoder() labelencoder_previsores_5 = LabelEncoder() [...] labelencoder_previsores_13 = LabelEncoder()
Aí você aplica cada instância separadamente a cada variável:
previsores[:,1] = labelencoder_previsores_1.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores_3.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores_5.fit_transform(previsores[:,5]) [...] previsores[:,13] = labelencoder_previsores_13.fit_transform(previsores[:,13])
E depois, no novo registro, somente o método transform:
novo_registro[:,1] = labelencoder_previsores_1.transform(novo_registro[:,1]) novo_registro[:,3] = labelencoder_previsores_3.transform(novo_registro[:,3]) novo_registro[:,5] = labelencoder_previsores_5.transform(novo_registro[:,5]) [...] novo_registro[:,13] = labelencoder_previsores_13.transform(novo_registro[:,13])
O ColumnTransformer não precisa mudar, já que ele processa mais de uma coluna por vez:
novo_registro = column_transformer.transform(novo_registro).toarray()
Aí é só chamar seu modelo com o método predict para classificar o novo registro.
-
This reply was modified 5 years, 2 months ago by
Fábio Spak.
23 de abril de 2021 at 16:11 #28469Desculpa Denny, acho que fiquei um pouco confuso. Bom, tentei seguir pelo o que entendi mas ao tentar passar o labelencoder com o método transform, está gerando um erro conforme a imagem abaixo. Uma observação que os dados do novo registro são exatamente iguais aos utiliziados na primeira linha da base de dados.
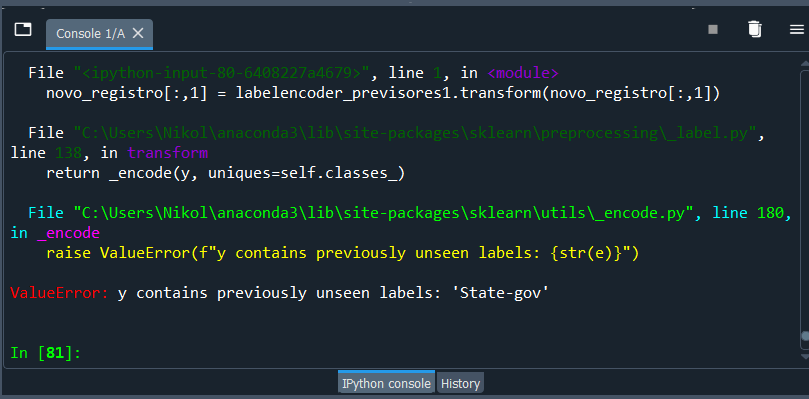
import pandas as pd import pickle from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np base = pd.read_csv('census.csv') previsores = base.iloc[:, 0:14].values classe = base.iloc[:, 14].values from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer labelencoder_previsores1 = LabelEncoder() labelencoder_previsores3 = LabelEncoder() labelencoder_previsores5 = LabelEncoder() labelencoder_previsores6 = LabelEncoder() labelencoder_previsores7 = LabelEncoder() labelencoder_previsores8 = LabelEncoder() labelencoder_previsores9 = LabelEncoder() labelencoder_previsores13 = LabelEncoder() previsores[:,1] = labelencoder_previsores1.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores3.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores5.fit_transform(previsores[:,5]) previsores[:,6] = labelencoder_previsores6.fit_transform(previsores[:,6]) previsores[:,7] = labelencoder_previsores7.fit_transform(previsores[:,7]) previsores[:,8] = labelencoder_previsores8.fit_transform(previsores[:,8]) previsores[:,9] = labelencoder_previsores9.fit_transform(previsores[:,9]) previsores[:,13] = labelencoder_previsores13.fit_transform(previsores[:,13]) column_tranformer = ColumnTransformer([('one_hot_encoder', OneHotEncoder(), [1, 3, 5, 6, 7, 8, 9, 13])],remainder='passthrough') previsores = column_tranformer.fit_transform(previsores).toarray() labelencoder_classe = LabelEncoder() classe = labelencoder_classe.fit_transform(classe) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() previsores = scaler.fit_transform(previsores) mlp = pickle.load(open('mlp_final.sav', 'rb')) resultado_mlp = mlp.score(previsores, classe) novo_registro = [[39,"State-gov",77516,"Bachelor",13,"Never-married","Adm-clerical","Not-in-family","White","Male",2174,0,40,"United-States"]] novo_registro = np.asarray(novo_registro) novo_registro[:,1] = labelencoder_previsores1.transform(novo_registro[:,1]) novo_registro[:,3] = labelencoder_previsores3.transform(novo_registro[:,3]) novo_registro[:,5] = labelencoder_previsores5.transform(novo_registro[:,5]) novo_registro[:,6] = labelencoder_previsores6.transform(novo_registro[:,6]) novo_registro[:,7] = labelencoder_previsores7.transform(novo_registro[:,7]) novo_registro[:,8] = labelencoder_previsores8.transform(novo_registro[:,8]) novo_registro[:,9] = labelencoder_previsores9.transform(novo_registro[:,9]) novo_registro[:,13] = labelencoder_previsores13.transform(novo_registro[:,13])
23 de abril de 2021 at 16:53 #28476Olá Nikolas, segue a resposta do instrutor Denny:
Tem duas causas potenciais: A primeira, verifique quais são os nomes das colunas de base. Aqui, o Pandas criou uma coluna 0 sem nome onde colocou os índices das instâncias, o que desalinha todas as operações de LabelEncoder. Se este for o caso, carregue os dados de novo com base = pd.read_csv(‘census.csv’, index_col = 0).
A segunda, se você pedir pra verificar os valores da coluna workclass com base[‘workclass’].tolist(), vai verificar que todos os nomes têm um espaço na frente. Eu abri o arquivo census.csv e este é o caso para todas as categorias. Então, em seu novo registro, adicione um espaço na frente de todos os nomes de categorias.
23 de abril de 2021 at 17:28 #28477Consegui.Era isso mesmo. Tem um espaço antes de alguns registros ali. Bom, até essa parte consegui fazer. Continuei com o processo e fiz o reshape para poder fazer o escalonamento e tudo mais. Mas agora o problema que quando vou passar o predict, meu modelo de treinamento usado foi com OneHotEncoder e ai gerou as variáveis dummy, que no caso aumentou minha base para 108 colunas. Ao tentar passar o predict ele não consegue por pelo fato do novo registro só possuir 14 colunas.
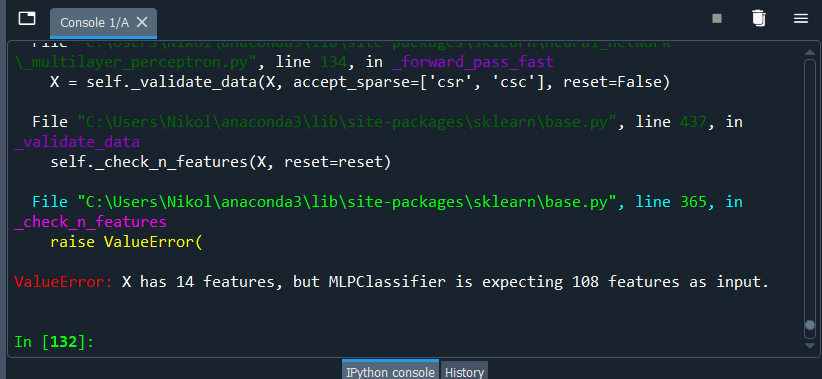
import pandas as pd import pickle from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np base = pd.read_csv('census.csv') previsores = base.iloc[:, 0:14].values classe = base.iloc[:, 14].values from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer labelencoder_previsores1 = LabelEncoder() labelencoder_previsores3 = LabelEncoder() labelencoder_previsores5 = LabelEncoder() labelencoder_previsores6 = LabelEncoder() labelencoder_previsores7 = LabelEncoder() labelencoder_previsores8 = LabelEncoder() labelencoder_previsores9 = LabelEncoder() labelencoder_previsores13 = LabelEncoder() previsores[:,1] = labelencoder_previsores1.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores3.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores5.fit_transform(previsores[:,5]) previsores[:,6] = labelencoder_previsores6.fit_transform(previsores[:,6]) previsores[:,7] = labelencoder_previsores7.fit_transform(previsores[:,7]) previsores[:,8] = labelencoder_previsores8.fit_transform(previsores[:,8]) previsores[:,9] = labelencoder_previsores9.fit_transform(previsores[:,9]) previsores[:,13] = labelencoder_previsores13.fit_transform(previsores[:,13]) column_tranformer = ColumnTransformer([('one_hot_encoder', OneHotEncoder(), [1, 3, 5, 6, 7, 8, 9, 13])],remainder='passthrough') previsores = column_tranformer.fit_transform(previsores).toarray() labelencoder_classe = LabelEncoder() classe = labelencoder_classe.fit_transform(classe) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() previsores = scaler.fit_transform(previsores) mlp = pickle.load(open('mlp_final.sav', 'rb')) resultado_mlp = mlp.score(previsores, classe) novo_registro = [[39," State-gov",77516," Bachelors",13," Never-married"," Adm-clerical"," Not-in-family"," White"," Male",2174,0,40," United-States"]] novo_registro = np.asarray(novo_registro) novo_registro[:,1] = labelencoder_previsores1.transform(novo_registro[:,1]) novo_registro[:,3] = labelencoder_previsores3.transform(novo_registro[:,3]) novo_registro[:,5] = labelencoder_previsores5.transform(novo_registro[:,5]) novo_registro[:,6] = labelencoder_previsores6.transform(novo_registro[:,6]) novo_registro[:,7] = labelencoder_previsores7.transform(novo_registro[:,7]) novo_registro[:,8] = labelencoder_previsores8.transform(novo_registro[:,8]) novo_registro[:,9] = labelencoder_previsores9.transform(novo_registro[:,9]) novo_registro[:,13] = labelencoder_previsores13.transform(novo_registro[:,13]) novo_registro = novo_registro.reshape(-1, 1) novo_registro = scaler.fit_transform(novo_registro) novo_registro = novo_registro.reshape(-1, 14) resposta_mlp = mlp.predict(novo_registro)23 de abril de 2021 at 19:12 #28478Olá Nikolas, segue a resposta do instrutor Denny:
Nikolas,
Você não deve fazer este reshape:
novo_registro = novo_registro.reshape(-1, 1)
porque os dados que o modelo recebe devem estar representados pelas instâncias nas linhas e atributos nas colunas. Então, o formato original já estava correto.
Ainda assim, depois do último LabelEncoder, faltou aplicar o ColumnTransformer que vai transformar as variáveis categóricas no formato one-hot, convertendo os 14 atributos originais para 108:
novo_registro = column_tranformer.transform(novo_registro).toarray()
e depois, finalmente, aplicar o scaler, mas novamente somente com o método transform:
novo_registro = scaler.transform(novo_registro)
Aí sim o registro pode ser passado ao modelo.
23 de abril de 2021 at 20:39 #28479Eu tentei realizar essas mudanças Denny mas não funcionou. Ao tentar fazer o column_tranformer ele acusa o erro da imagem. Dei uma pesquisada e alguns lugares falava para utilizar o OneHotEncoder(handle_unknown=’ignore’), mas não funcionou.
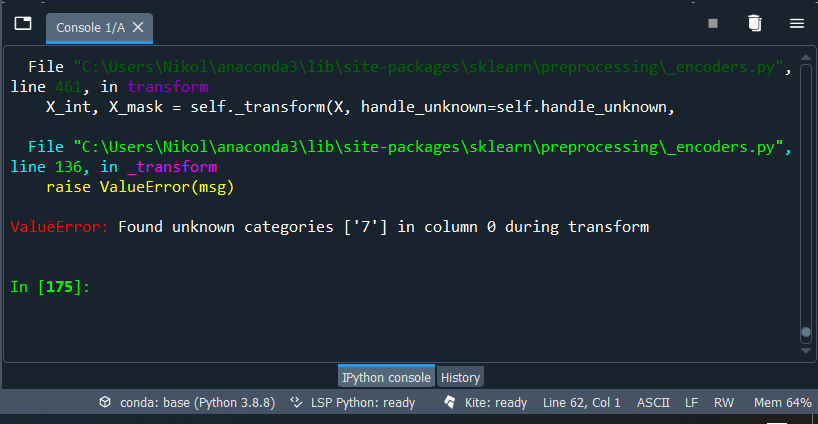
import pandas as pd import pickle from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np base = pd.read_csv('census.csv') previsores = base.iloc[:, 0:14].values classe = base.iloc[:, 14].values from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer labelencoder_previsores1 = LabelEncoder() labelencoder_previsores3 = LabelEncoder() labelencoder_previsores5 = LabelEncoder() labelencoder_previsores6 = LabelEncoder() labelencoder_previsores7 = LabelEncoder() labelencoder_previsores8 = LabelEncoder() labelencoder_previsores9 = LabelEncoder() labelencoder_previsores13 = LabelEncoder() previsores[:,1] = labelencoder_previsores1.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores3.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores5.fit_transform(previsores[:,5]) previsores[:,6] = labelencoder_previsores6.fit_transform(previsores[:,6]) previsores[:,7] = labelencoder_previsores7.fit_transform(previsores[:,7]) previsores[:,8] = labelencoder_previsores8.fit_transform(previsores[:,8]) previsores[:,9] = labelencoder_previsores9.fit_transform(previsores[:,9]) previsores[:,13] = labelencoder_previsores13.fit_transform(previsores[:,13]) column_tranformer = ColumnTransformer([('one_hot_encoder', OneHotEncoder(), [1, 3, 5, 6, 7, 8, 9, 13])],remainder='passthrough') previsores = column_tranformer.fit_transform(previsores).toarray() labelencoder_classe = LabelEncoder() classe = labelencoder_classe.fit_transform(classe) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() previsores = scaler.fit_transform(previsores) mlp = pickle.load(open('mlp_final.sav', 'rb')) resultado_mlp = mlp.score(previsores, classe) novo_registro = [[39," State-gov",77516," Bachelors",13," Never-married"," Adm-clerical"," Not-in-family"," White"," Male",2174,0,40," United-States"]] novo_registro = np.asarray(novo_registro) novo_registro[:,1] = labelencoder_previsores1.transform(novo_registro[:,1]) novo_registro[:,3] = labelencoder_previsores3.transform(novo_registro[:,3]) novo_registro[:,5] = labelencoder_previsores5.transform(novo_registro[:,5]) novo_registro[:,6] = labelencoder_previsores6.transform(novo_registro[:,6]) novo_registro[:,7] = labelencoder_previsores7.transform(novo_registro[:,7]) novo_registro[:,8] = labelencoder_previsores8.transform(novo_registro[:,8]) novo_registro[:,9] = labelencoder_previsores9.transform(novo_registro[:,9]) novo_registro[:,13] = labelencoder_previsores13.transform(novo_registro[:,13]) novo_registro = column_tranformer.transform(novo_registro).toarray() novo_registro = scaler.transform(novo_registro) resposta_mlp = mlp.predict(novo_registro)24 de abril de 2021 at 00:06 #28481Bom Denny, acho que agora consegui. Eu tive que colocar um parâmetro dentro do OneHotEncoder e também modificar o tipo de array do novo registro. Não sei se isso influencia, mas antes de trocar de array string para objeto, não estava conseguindo.
import pandas as pd import pickle from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np base = pd.read_csv('census.csv') previsores = base.iloc[:, 0:14].values classe = base.iloc[:, 14].values from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.compose import ColumnTransformer labelencoder_previsores1 = LabelEncoder() labelencoder_previsores3 = LabelEncoder() labelencoder_previsores5 = LabelEncoder() labelencoder_previsores6 = LabelEncoder() labelencoder_previsores7 = LabelEncoder() labelencoder_previsores8 = LabelEncoder() labelencoder_previsores9 = LabelEncoder() labelencoder_previsores13 = LabelEncoder() previsores[:,1] = labelencoder_previsores1.fit_transform(previsores[:,1]) previsores[:,3] = labelencoder_previsores3.fit_transform(previsores[:,3]) previsores[:,5] = labelencoder_previsores5.fit_transform(previsores[:,5]) previsores[:,6] = labelencoder_previsores6.fit_transform(previsores[:,6]) previsores[:,7] = labelencoder_previsores7.fit_transform(previsores[:,7]) previsores[:,8] = labelencoder_previsores8.fit_transform(previsores[:,8]) previsores[:,9] = labelencoder_previsores9.fit_transform(previsores[:,9]) previsores[:,13] = labelencoder_previsores13.fit_transform(previsores[:,13]) column_tranformer = ColumnTransformer([('one_hot_encoder', OneHotEncoder(handle_unknown='ignore'), [1, 3, 5, 6, 7, 8, 9, 13])],remainder='passthrough') previsores = column_tranformer.fit_transform(previsores).toarray() labelencoder_classe = LabelEncoder() classe = labelencoder_classe.fit_transform(classe) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() previsores = scaler.fit_transform(previsores) mlp = pickle.load(open('mlp_final.sav', 'rb')) resultado_mlp = mlp.score(previsores, classe) novo_registro = [[52," Self-emp-not-inc",209642," HS-grad",9," Married-civ-spouse"," Exec-managerial"," Husband"," White"," Male",0,0,45," United-States"]] novo_registro = np.asarray(novo_registro) novo_registro[:,1] = labelencoder_previsores1.transform(novo_registro[:,1]) novo_registro[:,3] = labelencoder_previsores3.transform(novo_registro[:,3]) novo_registro[:,5] = labelencoder_previsores5.transform(novo_registro[:,5]) novo_registro[:,6] = labelencoder_previsores6.transform(novo_registro[:,6]) novo_registro[:,7] = labelencoder_previsores7.transform(novo_registro[:,7]) novo_registro[:,8] = labelencoder_previsores8.transform(novo_registro[:,8]) novo_registro[:,9] = labelencoder_previsores9.transform(novo_registro[:,9]) novo_registro[:,13] = labelencoder_previsores13.transform(novo_registro[:,13]) novo_registro = np.asarray(novo_registro, object) novo_registro = column_tranformer.transform(novo_registro).toarray() novo_registro = scaler.transform(novo_registro) resposta_mlp = mlp.predict(novo_registro)25 de abril de 2021 at 09:39 #28493Olá Nikolas, segue a resposta do instrutor Denny:
Não precisa mudar o parâmetro do OneHotEncoder; com handle_unknown = ‘ignore’, você está dizendo para ele ignorar as categorias que não tenha visto no dataset de treinamento, mas se for algum outro tipo de erro relacionado ao tipo de dado por exemplo (que é o que houve), ele também vai ignorar a categoria, o que não é o comportamento desejado.
A outra transformação está correta, inclusive se você verificar o tipo de dado em previsores antes do column_transformer (com previsores.dtype), vai ver que é um objeto. Mas você pode simplificar um pouco o código já instanciando o novo_registro como array do tipo objeto:novo_registro = np.array([[39," State-gov",77516," Bachelors",13," Never-married"," Adm-clerical"," Not-in-family"," White"," Male",2174,0,40," United-States"]], object)
Parabéns por ter conseguido resolver esta última questão por conta, saber procurar as respostas pesquisando na internet é essencial para um bom profissional da área.
26 de abril de 2021 at 11:24 #28503Ah sim. Entendido Denny. Muito obrigado pelo suporte. Irei dar algumas simplificadas como você instruiu.
14 de maio de 2024 at 09:25 #44816Que bom que deu certo!
-
This reply was modified 5 years, 2 months ago by
-
AuthorPosts
- You must be logged in to reply to this topic.