Home › Forums › Fórum Deep Learning com Python de A a Z: O Curso Completo › Dúvida conceitual sobre a validação cruzada
- This topic has 3 replies, 2 voices, and was last updated 3 years, 6 months ago by
Denny Ceccon.
-
AuthorPosts
-
25 de janeiro de 2023 at 14:54 #39096
Se eu não entendi errado, a validação cruzada é usada para avaliar o desempenho das redes criadas variando a porção da base de dados que é utilizada para treinamento e teste. No vídeo, é dito que precisamos considerar o resultado médio de todas as redes (que no caso foi 0,79, variando de 0,66 a 0,91). Por que precisamos considerar o resultado médio? Não seria possível resgatar os pesos da rede que teve o desempenho de 0,91 e desconsiderar as demais redes que não tiveram um bom resultado, num cenário em que um score acima de 0,9 seja o suficiente para o meu estudo?
Pela explicação, deu a entender que as 10 redes criadas precisam ter um bom accuracy score.
26 de janeiro de 2023 at 15:59 #39106Olá Vinícius,
A validação cruzada serve para mostrar a capacidade de generalização do modelo. Suponha que nós façamos validação cruzada com 10 folds, 9 deles tenham ficado com desempenho similar mas o último tenha tido desempenho inferior, isto quer dizer que, dependendo da fração dos dados que utilizemos para treinamento, o desempenho da rede será diferente. No cenário ideal, todos os resultados devem ser parecidos (ou seja, o desvio padrão deve ser pequeno). Por isso não podemos escolher o modelo com melhor desempenho nesta etapa, já que este desempenho é um mero artefato da forma com que os dados foram divididos.
26 de janeiro de 2023 at 18:04 #39108Concordo que um bom desempenho da rede pode ter sido uma mera consequência da forma como os dados foram divididos, e também concordo que o cenário ideal é o que todos os resultados sejam parecidos.
Entretanto, vamos supor um novo exemplo de 10 folds: se houver uma rede com accuracy de 100%, enquanto os demais resultados variarem entre 0,80 a 0,90, aquela rede específica de 100%, se eu salvo o classificador desta e os seus respectivos pesos, essa rede pode ser considerada boa para que eu faça previsões com ela, já que ela se adaptou bem tanto para a base de treinamento, tanto para a de teste? Ou mesmo tendo accuracy de 100%, não necessariamente ela será boa, pois esse score foi obtido por uma mera ocasião na distribuição dos dados, já que os demais folds não tiveram resultados próximos ou iguais a 100% também?
26 de janeiro de 2023 at 19:10 #39109A segunda afirmação. O fato de um mesmo modelo treinado em um mesmo dataset ter desempenho diferente dependendo do split mostra que o modelo não aprendeu muito sobre a população de onde o dataset com que estamos trabalhando é uma amostra, mas sim apenas sobre aquela fração em que ele foi treinado/validado. Imagine que estejamos treinando um modelo para entender a relação entre x e y cujos dados disponíveis mostram a relação abaixo:
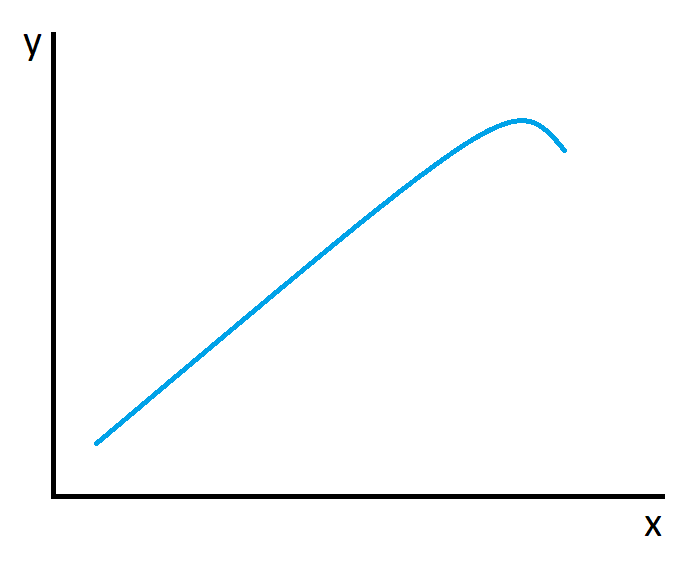
Se nós escolhermos uma regressão linear para modelar estes dados, o modelo vai desempenhar muito bem na fração linear da curva, mas muito mal na fração da extrema direita. Considerando ainda que estes dados são apenas uma amostra da população de dados, o desempenho pode ficar ainda pior quando estivermos fazendo predições com valores de x fora do intervalo de treinamento.
Mesmo que todos os folds tenham desempenho similar, ainda assim não temos certeza se o aprendizado na amostra pode ser extrapolado para a população, mas pelo menos é uma evidência a mais nesse sentido.
-
AuthorPosts
- You must be logged in to reply to this topic.