Home › Forums › Fórum Deep Learning com Python de A a Z: O Curso Completo › Mapas auto-organizaveis
- This topic has 12 replies, 2 voices, and was last updated 3 years, 11 months ago by
Denny Ceccon.
-
AuthorPosts
-
30 de junho de 2022 at 01:09 #35748
Professor eu tenho 3 dúvidas
-Os mapas autorganizaveis são melhores no geral que o KNN?
-Quando achamos o BMU para cada registro,fazemos um raio entorno do BMU e transformamos os “nós” que não BMU em valores similares o do BMU,mas como que definimos o número de clusters?
-Como eu faço pra pegar os ids,do registro conforme eles foram calssificadoas,por exemplo id 1 = cluster 0,id 2 = cluster 3,etc…
Obrigado
30 de junho de 2022 at 15:36 #35768Olá Caio,
- Não dá pra dizer que os SOMs são melhores que o KNN, são técnicas diferentes com objetivos similares, assim como árvores de decisão e redes neurais que podem ser utilizadas com os mesmos objetivos.
- Uma forma é como o professor mostrou na aula Mapas auto organizáveis – aprendizagem, onde o número de clusters é igual ao número de BMUs identificados na inicialização do mapa.
- Dê uma olhada neste exemplo no GitHub da biblioteca, a função
classifyfaz a classificação.
5 de julho de 2022 at 01:34 #35814passos do SOM
- Diferente das redes neurais tradicionais,não existem neuronios,exitem nós e esses nós vão receber pontos,de acordo com o número de entradas.
- Sendo assim,eles vão pegar um registro aleatório,vão calcular a distância desse registro com todos os nós,vão pegar o nó que teve a menor distância e esse nó vai ser o BMU.
- Achando o BMU,fazemos um raio entorno desse BMU,e transformamos os nós em volta com atributos parecidos com o do BMU.
Sendo assim,nessa área do mapa vamos ter um padrão nos atributos. - Então quando for fazer o mesmo processo,e pegarmos um registro parecido com o primeiro registro,muito provavelmente ele vai cair na mesma área do mapa.
Dúvidas
– Só que minha dúvida é o seguinte professor,no link que eu li sobre o SOM,o N iterations vai ser o número de vezes que vamos pegar um registro e realizar todo esse passo a passo,só que como sabemos quantos clusters foram formados,e como eles são formados?
. por exemplo professor,eu assisti dnv as aulas,só que vamos supor que eu tenha uma base de dados considerável,e fazendo o calculo eu descobri que tem que usar um total de 120 neuronios,e nessa base de dados 100 neuronios foram selecionados como BMU,quer dizer que vamos ter 100 clusters?
-E Queria saber se esses calculos são feitos um registro de cada vez ou pegas varios registros aleatoria e calcula tudo de uma vez
5 de julho de 2022 at 02:36 #35815Talvez eu esteja errado,mas pelo que eu entendi,esse mapa funciona quando ja sabemos o número de classes,como nas aulas do credit_data(aprovado e não aprovado),pois assim podemos colocar que vamos usar dois marcadores,e ele vai separar o mapa em 2 cluster,bolinha e quadrado
Obs:Caso eu não tenha me explicado muito bem,me avisa,professor.
5 de julho de 2022 at 11:05 #35816Olá Caio,
Te confesso que não sei exatamente como o algoritmo funciona em detalhes, não é um algoritmo muito utilizado hoje em dia então não é comum alguém se especializar nele, mas como se trata de um algoritmo de aprendizagem não-supervisionada, então é ele próprio quem determina o número de clusters (veja que nós nem passamos o número de clusters ou a variável
ypara o algoritmo treinar), dependendo de quantos BMUs são selecionados na primeira iteração. Mas justamente por isso, como o posicionamento inicial dos neurônios é feito aleatoriamente, a cada vez que você gera um SOM é possível que isto resulte em um número de BMUs diferente, o importante é que há essa tendência de os registros migrarem para regiões similares do mapa. Podemos dizer que é um algoritmo que apresenta várias possíveis soluções, mas todas elas são válidas.Eu desconfio que os cálculos são feitos todos de uma única vez, geralmente só fazemos em “batches” quando os dados não cabem todos na memória, mas teria que inspecionar o algoritmo com cuidado para ter uma resposta definitiva.
Se você quiser se aprofundar no assunto, sugiro procurar mais vídeos no YouTube, é geralmente como eu faço para entender melhor sobre algum método.
5 de julho de 2022 at 16:57 #35822obrigado professor,qual o algoritimo mais comum hoje em dia,o kNN?
5 de julho de 2022 at 17:19 #35823Para agrupamento não-supervisionado dá pra usar o KNN, que é o mais clássico. Não tenho experiência com as ferramentas mais recentes mas ouço falar bastante das que constam nesses dois artigos: https://towardsdatascience.com/unsupervised-learning-and-data-clustering-eeecb78b422a, https://towardsdatascience.com/t-sne-clearly-explained-d84c537f53a
10 de julho de 2022 at 12:54 #35870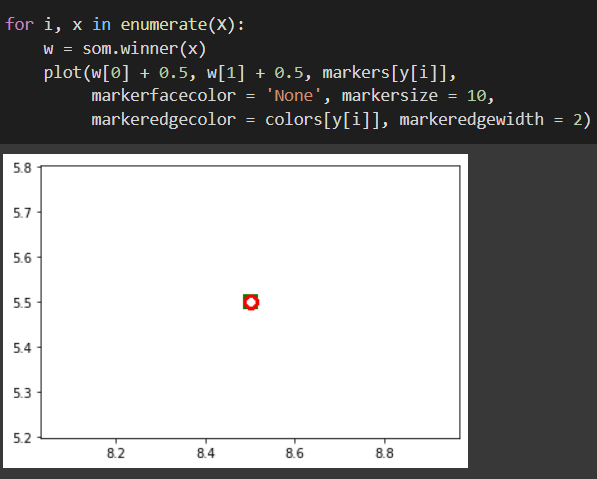
Professor sabe pq esta dando esse erro?
11 de julho de 2022 at 09:47 #35885Parece que seu código está colocando todos os registros no mesmo neurônio. Nessas horas, é melhor reiniciar o ambiente de execução com o código original e tentar de novo.
12 de julho de 2022 at 02:18 #35894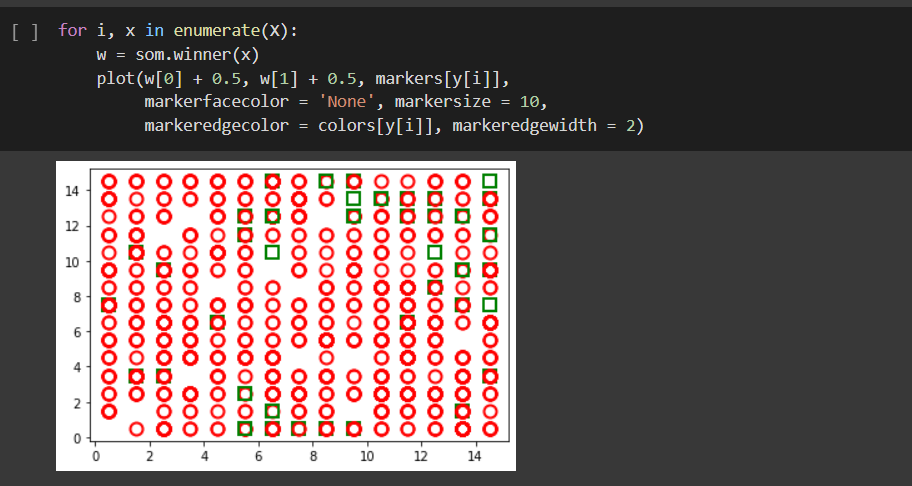
Professor,consegui arrumar o primeiro problema,só que agora não aparace as cores.
12 de julho de 2022 at 09:12 #35895Você tentou reexecutar o código original da aula?
12 de julho de 2022 at 18:00 #35904control c e control v,professor
12 de julho de 2022 at 20:26 #35905Acho que é porque você precisa rodar a parte do código onde plota o gráfico tudo de uma vez, porque os elementos do gráfico são adicionados um a um, e se você interromper o código no meio, só vai plotar a metade das informações.
Roda desde a linha
pcolor(som.distance_map().T)até o final em uma única célula. -
AuthorPosts
- You must be logged in to reply to this topic.