Home › Forums › Fórum Estatística para Ciência de Dados e Machine Learning › Naïve Bayes
- This topic has 3 replies, 2 voices, and was last updated 3 years, 4 months ago by
Denny Ceccon.
-
AuthorPosts
-
24 de fevereiro de 2023 at 21:38 #39707
Boa noite, Amigos
No item População e amostra item Introdução ao algoritmo Naïve Bayes.
Gostaria de saber de alguma ferramenta para montar a tabela de probabilidade.
(Lá você disse que a tabela pode ser montando em R).
Poderia me passar uma informação melhor
1 de março de 2023 at 16:08 #39745Olá William,
Não encontrei esta informação no vídeo para entender o contexto, você pode ser mais específico? Achei estranho você comentar R pois o curso é em Python.
8 de março de 2023 at 22:03 #39876Boa noite
Reformulando minha pergunta.
Como obter a tabela de probabilidade mostra na figura.
Ou seja, (com os dados categóricos gerar uma tabela de probabilidade ) qual função faz essa tarefa de forma direta.
Obrigado pela atenção.
Wiliam Regone
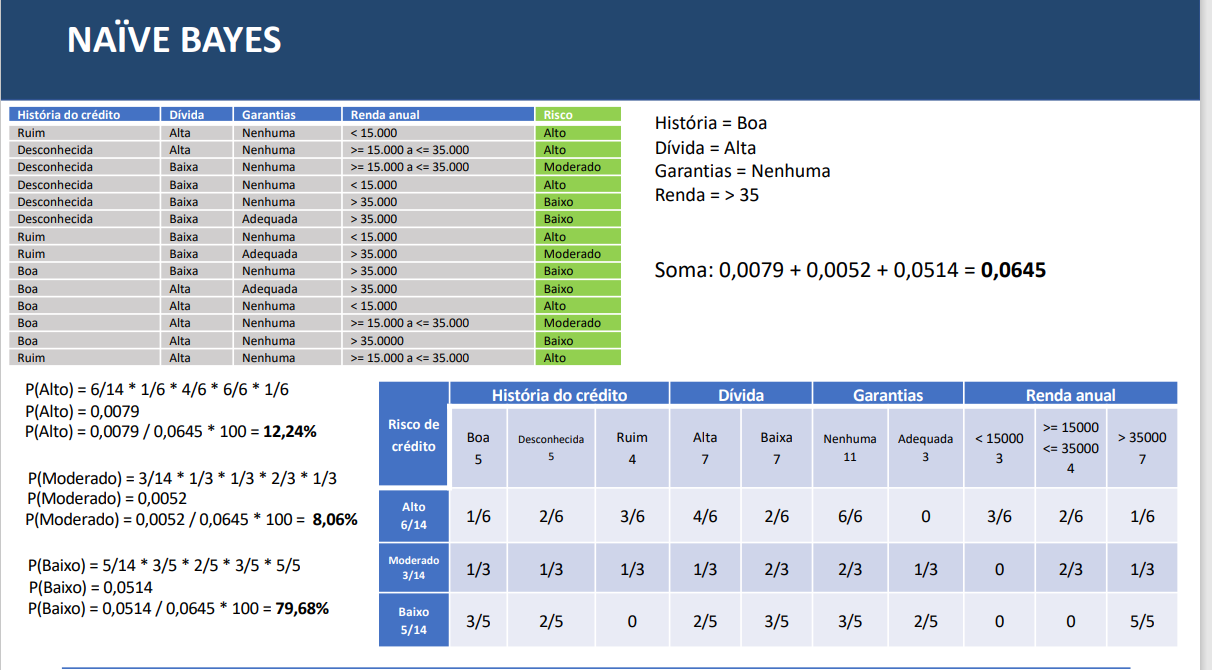 9 de março de 2023 at 09:57 #39885
9 de março de 2023 at 09:57 #39885Para problemas categóricos, você usaria a classe
CategoricalNB(documentação). Depois de treinar o modelo, as probabilidades estão no atributo feature_log_prob_, só que aqui você vai encontrar o log das probabilidades. Para converter para escala decimal, use a funçãonp.exp.Exemplo com dados inventados:
rng = np.random.RandomState(1) X = rng.randint(3, size=(10, 4)) y = np.array([1, 2, 2, 2, 1, 2, 1, 1, 1, 2]) from sklearn.naive_bayes import CategoricalNB clf = CategoricalNB(force_alpha=True) clf.fit(X, y) print(clf.feature_log_prob_) # [array([[-2.07944154, -0.69314718, -0.98082925], [-1.38629436, -0.69314718, -1.38629436]]), array([[-0.69314718, -1.38629436, -1.38629436], [-0.98082925, -0.98082925, -1.38629436]]), array([[-0.98082925, -0.98082925, -1.38629436], [-0.47000363, -1.38629436, -2.07944154]]), array([[-1.38629436, -0.69314718, -1.38629436], [-1.38629436, -1.38629436, -0.69314718]])] print(np.exp(np.array(clf.feature_log_prob_)) # array([[[0.125, 0.5 , 0.375], [0.25 , 0.5 , 0.25 ]], [[0.5 , 0.25 , 0.25 ], [0.375, 0.375, 0.25 ]], [[0.375, 0.375, 0.25 ], [0.625, 0.25 , 0.125]], [[0.25 , 0.5 , 0.25 ], [0.25 , 0.25 , 0.5 ]]])O array resultante tem shape (4, 2, 3) porque o exemplo tem 4 variáveis, 2 classes target e 3 categorias por variável.
-
AuthorPosts
- You must be logged in to reply to this topic.