Home › Forums › Fórum Assistentes Virtuais em Python: O Guia para Iniciantes › não está reconhecendo MCI?
- This topic has 1 reply, 2 voices, and was last updated 3 years, 3 months ago by
Dalton Vargas.
-
AuthorPosts
-
13 de abril de 2023 at 17:31 #40212
import pyttsx3
import speech_recognition as sr
from playsound import playsound
import random
import datetime
hour = datetime.datetime.now().strftime(‘%H:%M’)
#print(hour)
date = datetime.date.today().strftime(‘%d/%B/%Y’)
#print(date)
date = date.split(‘/’)
#print(date)
import webbrowser as wb
import tensorflow as tf
import numpy as np
import librosa
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from modules import carrega_agenda, comandos_respostas
comandos = comandos_respostas.comandos
respostas = comandos_respostas.respostas
#print(comandos)
#print(respostas)meu_nome = ‘Ana’
# Windows
chrome_path = ‘C:/Program Files/Google/Chrome/Application/chrome.exe %s’def search(frase):
wb.get(chrome_path).open(‘https://www.google.com/search?q=’ + frase)#search(‘linguagem python’)
MODEL_TYPES = [‘EMOÇÃO’]
def load_model_by_name(model_type):
if model_type == MODEL_TYPES[0]:
model = tf.keras.models.load_model(‘C:/Users\ppeli\PycharmProjects\Assistente_virtual\curso_assistente1\models\speech_emotion_recognition.hdf5’)
model_dict = sorted(list([‘neutra’, ‘calma’, ‘feliz’, ‘triste’, ‘nervosa’, ‘medo’, ‘nojo’, ‘surpreso’]))
SAMPLE_RATE = 48000
return model, model_dict, SAMPLE_RATE#print(load_model_by_name(‘EMOÇÃO’))
#print(load_model_by_name(‘EMOÇÃO’)[0].summary())model_type = ‘EMOÇÃO’
loaded_model = load_model_by_name(model_type)def predict_sound(AUDIO, SAMPLE_RATE, plot = True):
results = []
wav_data, sample_rate = librosa.load(AUDIO, sr=SAMPLE_RATE)
#print(wav_data)
#print(wav_data.shape)
clip, index = librosa.effects.trim(wav_data, top_db=60, frame_length=512, hop_length=64)
splitted_audio_data = tf.signal.frame(clip, sample_rate, sample_rate, pad_end=True, pad_value=0)
for i, data in enumerate(splitted_audio_data.numpy()):
print(‘Audio split: ‘, i)
print(data)
print(data.shape)
mfccs_feactures = librosa.feature.mfcc(y = data, sr = sample_rate, n_mfcc=40)
print(mfccs_feactures.shape)
print(mfccs_feactures)
mfccs_scaled_feactures = np.mean(mfccs_feactures.T, axis = 0)
mfccs_scaled_feactures = mfccs_scaled_feactures.reshape(1,-1)
print(mfccs_scaled_feactures.shape)
#bath
mfccs_scaled_feactures = mfccs_scaled_feactures[:,:,np.newaxis]
print(mfccs_scaled_feactures.shape)predictions = loaded_model[0].predict(mfccs_scaled_feactures, batch_size=32)
print(predictions)
print(predictions.sum())
if plot:
plt.figure(figsize=(len(splitted_audio_data), 5))
plt.barh(loaded_model[1], predictions[0])
plt.tight_layout()
plt.show()predictions = predictions.argmax(axis = 1)
print(predictions)
predictions = predictions.astype(int).flatten()
predictions = loaded_model[1] [predictions[0]]
results.append(predictions)
print(results)result_str = ‘PARTE’ + str(i) + ‘: ‘ + str(predictions).upper()
#print(result_str)count_results = [[results.count(x), x] for x in set(results)]
#print(count_results)#print(max(count_results))
return max(count_results)#predict_sound(‘triste.wav’, loaded_model[2], plot=False)
def play_music_youtube(emocao):
play = False
if emocao == ‘triste’ or emocao == ‘medo’:
wb.get(chrome_path).open (‘https://www.youtube.com/watch?v=k32IPg4dbz0&ab_channel=Amelhorm%C3%BAsicainstrumental’)
play = True
if emocao == ‘nervosa’ or emocao == ‘surpreso’:
wb.get(chrome_path).open(‘https://www.youtube.com/watch?v=pWjmpSD-ph0&ab_channel=CassioToledo’)
play = True
return play#play_music_youtube(‘nervosa’)
#emocao = predict_sound(‘triste.wav’, loaded_model[2], plot=False)
#print(emocao)
#play_music_youtube(emocao[1])def speak(audio):
engine = pyttsx3.init()
engine.setProperty(‘rate’, 150) # número de palavras por minuto
engine.setProperty(‘volume’, 1) # min: 0, max:1
engine.say(audio)
engine.runAndWait()#speak(‘testando o sintetizador de voz da assistente’)
def listen_microphone():
microfone = sr.Recognizer()
with sr.Microphone() as source:
microfone.adjust_for_ambient_noise(source, duration=0.8)
print(‘Ouvindo:’)
audio = microfone.listen(source)
with open(‘recordings/speech.wav’, ‘wb’) as f:
f.write(audio.get_wav_data())
try:
frase = microfone.recognize_google(audio, language=’pt-BR’)
print(‘Você disse: ‘ + frase)
except sr.UnknownValueError:
frase = ”
print(‘Não entendi’)
return frase#listen_microphone()
def test_models():
audio_source = ‘C:/Users\ppeli\PycharmProjects\Assistente_virtual\curso_assistente1/recordings\speech.wav’
prediction = predict_sound(audio_source, loaded_model[2], plot = False)
return prediction#print(test_models())
playing = False
mode_control = False
print(‘[INFO] Pronto para começar!’)
playsound(‘n1.mp3’)while (1):
result = listen_microphone()if meu_nome in result:
result = str(result.split(meu_nome + ‘ ‘)[1])
result = result.lower()
print(‘Acionou a assistente!’)
else:
playsound(‘n3.mp3’)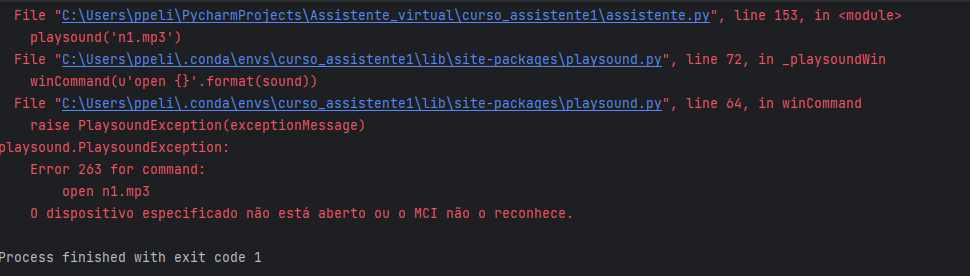
<div id=”acfifjfajpekbmhmjppnmmjgmhjkildl” class=”acfifjfajpekbmhmjppnmmjgmhjkildl”></div>14 de abril de 2023 at 08:54 #40234Oi Edson!
Esta questão já foi respondida a você no tópico do aluno Michael. Segue o link: https://iaexpert.academy/forums/topic/erro-na-reproducao-de-audios-mp3-ao-executar-assistente-virtual/
-
AuthorPosts
- You must be logged in to reply to this topic.