Home › Forums › Fórum Visão Computacional: O Guia Completo › Overfitining
- This topic has 1 reply, 2 voices, and was last updated 4 years, 4 months ago by
 Gabriel Alves.
Gabriel Alves.
-
AuthorPosts
-
1 de fevereiro de 2022 at 10:52 #33041
Bom dia, professor
Estou treinando uma rede resnet tal como foi usada em alguns vídeos do curso com foco em transfer learning. No entanto, quando aplico a metodologia em meu dataset (personalizado, mas com boa resolução), tenho uma alta acurácia em meu conjunto de treinamento desde a primeira época, mas, quando faço uso do meu conjunto de validação, a acurácia é baixíssima. Vide figura abaixo:
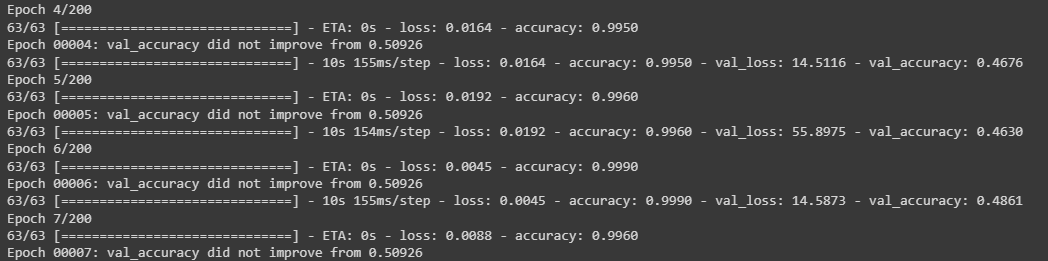
Usei a seguinte estrutura:

Já fiz algumas alterações na estrutura do modelo, aumentando e diminuindo camadas Densas e de Dropout, mas mesmo assim não funcionou. Gostaria que me ajudassem quanto a isso, por favor. Ficarei imensamente grato! (caso precisem, posso compartilhar meu notebook e a finalidade da minha pesquisa com você)
Aproveitando, gostaria de saber o que pode ser feito para ter um melhor desempenho usando resnet? Por exemplo, suponhamos que estivéssemos usando um conjunto de dados personalizado; o que espera-se do treinamento se em detrimento de congelar os pesos das camadas, eles forem treinados?
10 de fevereiro de 2022 at 10:38 #33090Olá Rafael!
Na verdade isso é uma coisa que depende muito do dataset com o qual você está trabalhando, pois está ligado às “características” do seu set de treinamento. Primeiramente, qual dataset você está tentando fazer transfer learning? E quantas imagens ele possui (pra treinamento e validação)?
Pois em alguns conjuntos é necessário ajustes mais complexos já que isso depende das características dos próprios dados (nesse caso, imagens).
Outra coisa: é possível aumentar a quantidade de imagens em seu dataset? Se sim, sugiro fazer esse experimento e realizar o treinamento novamente. Se a acurácia do set de validação está ruim significa que o modelo não está conseguindo aprender com os dados e extrair as features relevantes necessárias para ter um bom desempenho.
Revise o dataset e garanta que as imagens de treinamento sejam uma boa referência para que o modelo consiga prever o set de validação, pois não adianta as imagens de validação serem muito diferentes também e esperar que com poucos ajustes o modelo vai aprender a identificar bem esses padrões. Caso não possa capturar mais imagens, pode usar a técnica de Data Augmentation.
Minha recomendação então é fazer mais experimentos nessas camadas conforme você está fazendo – deixo como sugestão a leitura desse guia aqui que acho que vai te ajudar.
Além disso, o que vai melhorar os resultados é descongelar (unfreeze) as camadas do modelo. Esse método de manter as camadas congeladas garante uma melhora incrivel na velocidade de treinamento, porém fica muito limitado à acurácia, então se precisa melhorar essa acurácia – especialmente porque a precisão no set de validação está ruim – o mais indicado é testar isso (ou seja, diminuir as camadas congeladas e aumentar camadas treináveis).
-
AuthorPosts
- You must be logged in to reply to this topic.