Home › Forums › Fórum Sumarização de Textos com Processamento de Linguagem Natural › Similaridade sentenças em dataframes – Similaridade entre sentenças 2
Tagged: Similaridade entre sentenças 2
- This topic has 9 replies, 2 voices, and was last updated 4 years ago by
Denny Ceccon.
-
AuthorPosts
-
30 de junho de 2022 at 15:13 #35766
COmo faço para ver a similaridade de uma coluna x texto da outra? Por exemplo queria ver todos os textos de task1 x todos os textos de task2
import pandas as pd df1 = { "Task1": ["Appoint department heads or managers and assign or delegate responsibilities to them", "Analyze operations to assess the performance of a company or its staff in meeting objectives or to determine areas of potential cost reduction, program improvement, or policy change", "Directing, planning or implementing policies, objectives or activities of organizations or businesses to ensure continuity of operations, maximize return on investment or increase productivity", "Prepare budgets for approval, including those for program funding or implementation", "Establish departmental responsibilities and coordinate roles across departments and sites", "Give speeches, write articles, or present information at meetings or conventions to promote services, exchange ideas, or achieve goals","Prepare or report on activities, expenses, budgets, statutes or government decisions or other items that affect program business or services", "Organize or approve promotional campaigns"]} #load data into a DataFrame object: df1 = pd.DataFrame(df1) df2 = { "Task2": ["Define unit to participate in the production process", "Apply resources, according to the company's mission", "Sign agreements, agreements and contracts", "Supervise the execution of commercial, industrial, administrative and financial activity plans", "Interact with government agencies", "Define guidelines for contracting infrastructure services", "Evaluate the quality of the services provided", "Manage purchases and contracts", "Plan strategic actions for people management", "Discuss budget distribution between areas", "Demonstrate oral and written communication skills", "Sign agreements, agreements and contracts"]} df2 = pd.DataFrame(df2) df_final = pd.concat([df1,df2], axis=1)4 de julho de 2022 at 10:56 #35799Olá Shin,
Você vai precisar comparar as sentenças individualmente usando um loop:
matriz_similaridade = [] for sent1 in df_final['Task1']: vetor_similaridade = [] for sent2 in df_final['Task2']: vetor_similaridade.append(calcula_similaridade_sentencas(sent1, sent2)) matriz_similaridade.append(vetor_similaridade) matriz_similaridade = np.array(matriz_similaridade)O resultado vai ser uma matriz com os valores de similaridade entre todos os pares de sentenças.
-
This reply was modified 4 years ago by
4 de julho de 2022 at 14:34 #35805Esta dando erro de syntax.
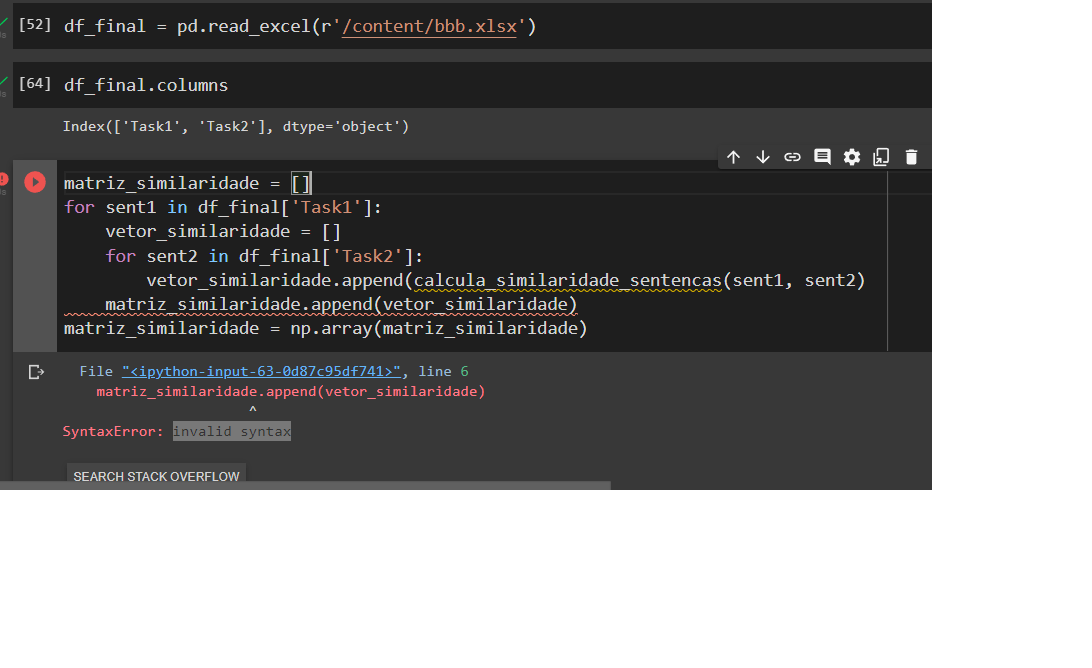 4 de julho de 2022 at 15:06 #35807
4 de julho de 2022 at 15:06 #35807Faltou fechar um parênteses na linha de cima.
4 de julho de 2022 at 16:12 #35809Entendi, mas é que quando eu fiz isso na primeira vez que tentei apareceu isso aqui : name ‘calcula_similaridade_sentencas’ is not defined
4 de julho de 2022 at 16:38 #35811Você precisa copiar a função do Colab da aula, ou colar seu código lá.
5 de julho de 2022 at 14:22 #35818Denny, eu sou meio burro, entao se tu puder me dar uma moral eu agradeço. O que tenho que mudar ali na funçao? sentença para sent1? se puder me ajudar…
def calcula_matriz_similaridade(sentencas):
matriz_similaridade = np.zeros((len(sentencas), len(sentencas)))
#print(matriz_similaridade)
for i in range(len(sentencas)):
for j in range(len(sentencas)):
if i == j:
continue
matriz_similaridade[i][j] = calcula_similaridade_sentencas(sentencas[i], sentencas[j])return matriz_similaridade
O que mudo aqui?
5 de julho de 2022 at 15:39 #35821Adiciona o seu código (definição do
df_final) mais o meu código neste ponto do notebook: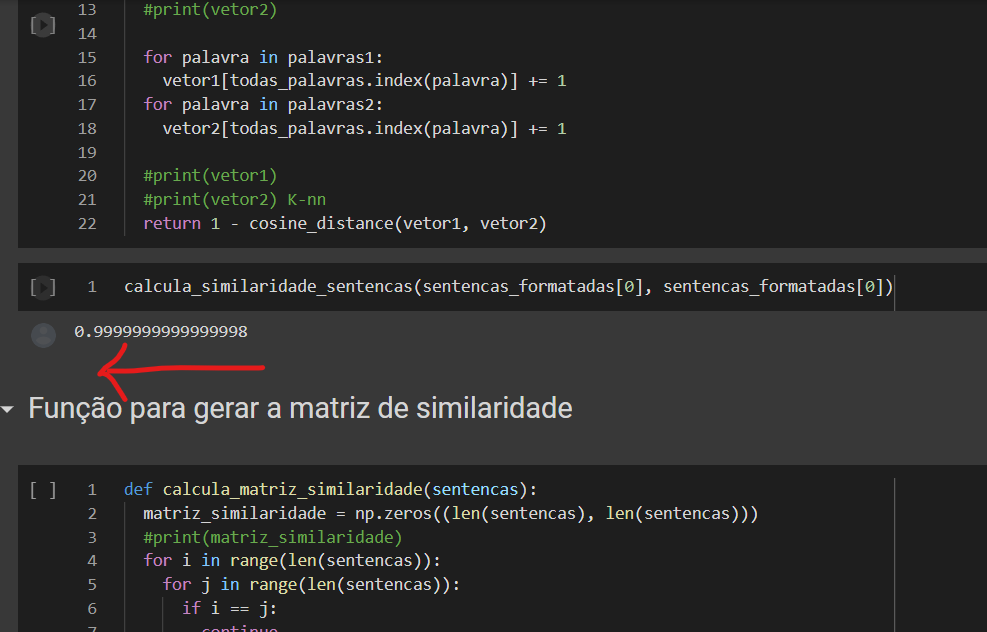 6 de julho de 2022 at 16:32 #35835
6 de julho de 2022 at 16:32 #35835Talvez o meu problema seja anterior, na parte de def calcula similaridade
df1 = { "Task1": ["Appoint department heads or managers and assign or delegate responsibilities to them", "Analyze operations to assess the performance of a company or its staff in meeting objectives or to determine areas of potential cost reduction, program improvement, or policy change", "Directing, planning or implementing policies, objectives or activities of organizations or businesses to ensure continuity of operations, maximize return on investment or increase productivity", "Prepare budgets for approval, including those for program funding or implementation", "Establish departmental responsibilities and coordinate roles across departments and sites", "Give speeches, write articles, or present information at meetings or conventions to promote services, exchange ideas, or achieve goals","Prepare or report on activities, expenses, budgets, statutes or government decisions or other items that affect program business or services", "Organize or approve promotional campaigns"]} #load data into a DataFrame object: df1 = pd.DataFrame(df1) df2 = { "Task2": ["Define unit to participate in the production process", "Apply resources, according to the company's mission", "Sign agreements, agreements and contracts", "Supervise the execution of commercial, industrial, administrative and financial activity plans", "Interact with government agencies", "Define guidelines for contracting infrastructure services", "Evaluate the quality of the services provided", "Manage purchases and contracts", "Plan strategic actions for people management", "Discuss budget distribution between areas", "Demonstrate oral and written communication skills", "Sign agreements, agreements and contracts"]} df2 = pd.DataFrame(df2) df_final = pd.concat([df1,df2], axis=1) def calcula_matriz_similaridade(sentencas): matriz_similaridade = [] for sent1 in df_final['Task1']: vetor_similaridade = [] for sent2 in df_final['Task2']: vetor_similaridade.append(calcula_similaridade_sentencas(sent1, sent2)) matriz_similaridade.append(vetor_similaridade) matriz_similaridade = np.array(matriz_similaridade) return matriz_similaridadeapareceu isso "expected string or bytes-like object"
6 de julho de 2022 at 17:41 #35836Não precisa botar dentro de uma função, pode ser exatamente como eu escrevi:
import pandas as pd df1 = {"Task1": ["Appoint department heads or managers and assign or delegate responsibilities to them", "Analyze operations to assess the performance of a company or its staff in meeting objectives or to determine areas of potential cost reduction, program improvement, or policy change", "Directing, planning or implementing policies, objectives or activities of organizations or businesses to ensure continuity of operations, maximize return on investment or increase productivity", "Prepare budgets for approval, including those for program funding or implementation", "Establish departmental responsibilities and coordinate roles across departments and sites", "Give speeches, write articles, or present information at meetings or conventions to promote services, exchange ideas, or achieve goals","Prepare or report on activities, expenses, budgets, statutes or government decisions or other items that affect program business or services", "Organize or approve promotional campaigns"]} #load data into a DataFrame object: df1 = pd.DataFrame(df1) df2 = { "Task2": ["Define unit to participate in the production process", "Apply resources, according to the company's mission", "Sign agreements, agreements and contracts", "Supervise the execution of commercial, industrial, administrative and financial activity plans", "Interact with government agencies", "Define guidelines for contracting infrastructure services", "Evaluate the quality of the services provided", "Manage purchases and contracts", "Plan strategic actions for people management", "Discuss budget distribution between areas", "Demonstrate oral and written communication skills", "Sign agreements, agreements and contracts"]} df2 = pd.DataFrame(df2) df_final = pd.concat([df1,df2], axis=1) matriz_similaridade = [] for sent1 in df_final['Task1']: vetor_similaridade = [] for sent2 in df_final['Task2']: vetor_similaridade.append(calcula_similaridade_sentencas(sent1, sent2)) matriz_similaridade.append(vetor_similaridade) matriz_similaridade = np.array(matriz_similaridade) -
This reply was modified 4 years ago by
-
AuthorPosts
- You must be logged in to reply to this topic.