Forum Replies Created
-
AuthorPosts
-
Olá Jefferson,
Parace que você está utilizando Linux certo?
Seguem algumas sugestões para corrigir este problema:
Tente instalar a versão mais recente do GCC:
- sudo apt update
sudo apt install build-essential gcc-12 g++-12 -y
Depois de instalar, ajuste o link simbólico da biblioteca para usar a nova versão:
- sudo ln -sf /usr/lib/gcc/x86_64-linux-gnu/12/libstdc++.so.6 /usr/lib/x86_64-linux-gnu/libstdc++.so.6
Caso a solução acima não funcione, tente reinstalar o PyAudio:
- sudo pip uninstall pyaudio
- sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
sudo apt-get install ffmpeg libav-tools
sudo pip install pyaudio
referência das soluções: https://stackoverflow.com/questions/20023131/cannot-install-pyaudio-gcc-error
Olá Fredis,
Isso geralmente ocorre devido a problemas com a configuração do ambiente ou com o arquivo em si.
Seguem algumas sugestões:
- verifique se a extensão do arquivo está correta (.py, arquivo.py);
- se você estiver usando o VSCode, precisa configurar o interpretador Python:
- pressione Ctrl + Shift + P (ou Cmd + Shift + P no macOS)
- digite Python: Select Interpreter e selecione-o
- escolha a versão do Python instalada no seu sistema
- verifique se o arquivo está salvo em uma pasta, e você abriu essa pasta no VSCode como um workspace
ah beleza Julio,
nesse caso é aquilo mesmo que expliquei na mensagem anterior.
Olá Julio,
desculpe, mas não entendi completamente a sua dúvida. Você está perguntando como fazer a classificação quando os nomes das classes são diferentes (no caso de estar utilizando um dataset diferente da Urban8k)?
Se for isso, a resposta é sim! É necessário ajustar alguns pontos no script para adaptar o modelo a um novo dataset. Segue abaixo onde você pode fazer essas modificações:
Dicionário de Classes (sound_list ou equivalente):
- verifique onde o dicionário de classes está definido no notebook
- atualize os nomes das classes para refletir as categorias da nova base de dados
- verifique se esses nomes correspondem exatamente aos metadados ou labels presentes na base
Carregamento e organização dos Dados:
- a UrbanSound8K usa arquivos organizados em diretórios por classe. Se sua nova base tem uma estrutura diferente (arquivos soltos ou outro tipo de metadados), ajuste a função de leitura para corresponder ao novo formato
- modifique o caminho dos dados no script (se necessário) para apontar para a localização correta da nova base
Pré-processamento de Áudio:
- o script pode estar usando um formato específico (WAV). Confirme se a nova base utiliza o mesmo formato ou adapte o código para converter os arquivos de áudio (de MP3 para WAV).
- verifique se os parâmetros de amostragem (sample rate) e duração dos clipes são compatíveis com os da nova base
Extração de Features (MFCC ou outras):
- bases diferentes podem demandar features específicas. Se a nova base exigir outra abordagem, ajuste a função de extração de MFCC ou adicione novos tipos de features, como espectrogramas ou Chroma
Modelo e mapeamento das Classes:
- ajuste a camada final do modelo (output layer) para o número correto de classes da nova base
- se necessário, revise o label encoding para garantir que o mapeamento das classes esteja correto ao longo do pipeline
Avaliação e métricas:
- caso a nova base tenha desbalanceamento entre as classes, pode ser interessante incluir técnicas de balanceamento (class_weight ou oversampling)
- revise as métricas utilizadas (accuracy pode não ser suficiente em casos de desbalanceamento)
Olá Glauco,
Seguem algumas sugestões do próprio site do pypi:
Selecione o pacote correto para seu ambiente:
- Existem quatro pacotes diferentes, mas vou listar somente as opções 1 e 2 abaixo, e você deve SELECIONAR APENAS UM DELES . Não instale vários pacotes diferentes no mesmo ambiente. Todos os pacotes usam o mesmo namespace (cv2). Se você instalou vários pacotes diferentes no mesmo ambiente, desinstale todos eles pip uninstall e reinstale apenas um pacote.
Desinstale as versões atuais do OpenCV e OpenCV-Contrib e instale a mesma versão que foi utilizada durante o curso. Abaixo, estão os comandos necessários:
- Desinstalar o OpenCV-Contrib:
pip uninstall opencv-contrib-python –user
- Desinstalar o OpenCV:
pip uninstall opencv-python –user
- Instalar a versão 4.5.2 do OpenCV:
pip install opencv-python==4.5.2 –user
31 de julho de 2024 at 08:58 in reply to: Erro: ‘AttributeError: ‘NoneType’ object has no attribute’ #45672Perfeito Glauco, que bom que deu certo!
26 de julho de 2024 at 08:18 in reply to: Erro: ‘AttributeError: ‘NoneType’ object has no attribute’ #45658Certo Glauco,
Tente usar o caminho absoluto do vídeo:
* no VSCode, clique com o botão direito do mouse sobre o vídeo e selecione ‘Copy Path’. Em seguida, cole esse caminho na atribuição da variável VIDEO_SOURCE.
Se isso também não funcionar, tente usar um vídeo diferente. Pode ser que o vídeo ‘Cars.mp4’ tenha sido corrompido durante o download do projeto. Nesse caso, vale a pena tentar baixar o vídeo novamente.
25 de julho de 2024 at 08:10 in reply to: Erro: ‘AttributeError: ‘NoneType’ object has no attribute’ #45654Olá Glauco,
Conforme a primeira mensagem de erro indica, há um erro de sintaxe ao informar o path do seu vídeo de entrada (VIDEO_SOURCE), com isso seu vídeo não está sendo carregado corretamente e por isso ocorre o segundo erro de que ‘o atributo shape não existe’. Ajustando a barra \ para / deve funcionar corretamente.
Aplicando a correção deve ficar assim:
VIDEO_SOURCE = ‘videos/Cars.mp4′
-
This reply was modified 2 years ago by
Dalton Vargas.
Entendi.
O modelo sempre tentará classificar todas as ocorrências de som. Isso significa que, mesmo para sons desconhecidos, ele tentará atribuir uma classificação à classe mais correspondente. O modelo recebe um fluxo contínuo de informações ao longo da onda sonora e aplica uma classificação para cada janela de som. Para que uma classificação seja desconsiderada, ela deve ser menor que um limiar pré-definido. No entanto, isso não significa que o som não foi classificado, apenas que a classificação foi inferior ao limiar. Você pode considerar que os sons com classificações inferiores ao limiar sejam desconhecidos.
Perfeito Cesar! Que bom que deu certo.
Certo Cesar,
Se você tem o identificador da voz anotado em seu dataset, então a ideia é a mesma que mencionei acima. Você usa a classe que identifica a voz para treinar seu modelo.
Olá Cesar,
O conjunto de dados que você mencionou é o RAVDESS? Se sim, o ator neste dataset identifica se é homem ou mulher:
- Ator (01 a 24. Os atores com números ímpares são homens, os atores com números pares são mulheres).
Em resumo, a mudança que você precisa fazer utilizando o mesmo script da classificação de emoção, é definir o atributo ator como classe. Por exemplo:
X = np.array(extracted_features_df[‘feature’].tolist())
y = np.array(df.actors.tolist())
O restante do script permanece inalterado, exceto pela definição da estrutura da rede neural, onde sugiro que você experimente e ajuste conforme necessário. Pode ser que uma estrutura menos complexa seja suficiente, já que a classificação envolve apenas duas classes (feminino e masculino).
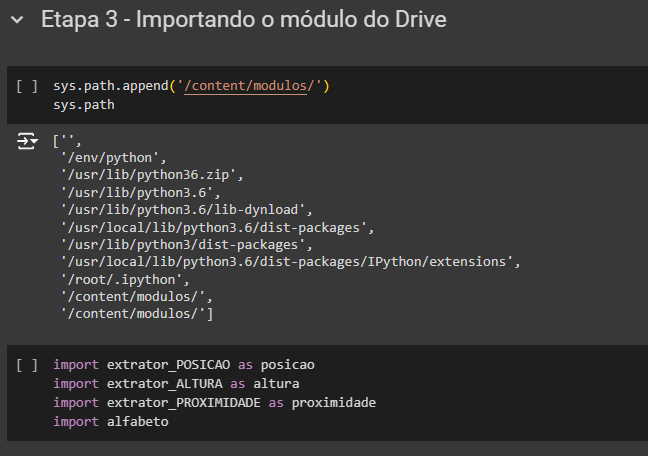
Olá Tamires,
Os componentes extrator_POSICAO, extrator_ALTURA e extrator_PROXIMIDADE são módulos e não bibliotecas, por isso o comando pip install não se aplica a eles.
Para que esses módulos sejam reconhecidos no seu script, é necessário adicionar os caminhos (paths) conforme demonstrado na vídeo aula.
Olá Tamires,
O erro “BadZipFile” pode aparecer se o arquivo zip foi corrompido devido a um erro durante a transmissão do arquivo.
Tente excluir o arquivo imagens.zip do seu Drive e fazer o upload novamente.
16 de maio de 2024 at 08:09 in reply to: Classificação de Emoções pela Fala – Rede pre treinada ou base em portugues #44904Olá Hugo,
(Ótima pergunta!!)
Ainda que o conjunto de dados usado para treinar o modelo seja em inglês, a natureza da detecção de emoções baseia-se mais na entonação e padrões de fala do que no idioma específico. Em outras palavras, a classificação das emoções em áudio é mais influenciada pela maneira como as emoções são expressas vocalmente, que é algo universal entre os seres humanos, do que pelo idioma em si. Por exemplo, a expressão de tristeza em áudio, tanto em inglês quanto em português, tende a compartilhar características acústicas semelhantes, tornando o idioma menos relevante para a precisão do modelo.
- sudo apt update
-
AuthorPosts