Forum Replies Created
-
AuthorPosts
-
Então o nome que está na primeira linha do conexoes[‘Full Name’] tem que ser o mesmo da primeira linha do convites[‘From’]?
-Caso seja igual a True vai retornar no nome da empresa?
então ele vai pegar palavra por palavra,verificar o documneto(nesse caso são frases),vai verificar qual palavra está presente no doc(frase),se estiver presente =True,se não= False?
professor,poderia me ajudar a entender essa parte da função
caracteristicas[‘%s’ % palavra] = (palavra in doc)
e uma redeu neural normal de lcassificação,pode ser usado para classificar textos,após transformar os dados em números?
eu digo no sentido para a classificação de uma frase
control c e control v,professor
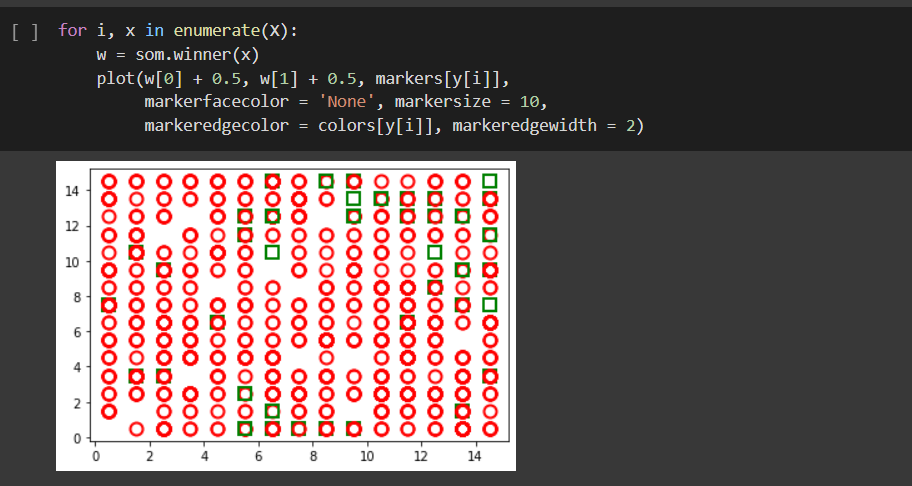
Professor,consegui arrumar o primeiro problema,só que agora não aparace as cores.
Professor sabe pq esta dando esse erro?
obrigado professor,qual o algoritimo mais comum hoje em dia,o kNN?
Talvez eu esteja errado,mas pelo que eu entendi,esse mapa funciona quando ja sabemos o número de classes,como nas aulas do credit_data(aprovado e não aprovado),pois assim podemos colocar que vamos usar dois marcadores,e ele vai separar o mapa em 2 cluster,bolinha e quadrado
Obs:Caso eu não tenha me explicado muito bem,me avisa,professor.
passos do SOM
- Diferente das redes neurais tradicionais,não existem neuronios,exitem nós e esses nós vão receber pontos,de acordo com o número de entradas.
- Sendo assim,eles vão pegar um registro aleatório,vão calcular a distância desse registro com todos os nós,vão pegar o nó que teve a menor distância e esse nó vai ser o BMU.
- Achando o BMU,fazemos um raio entorno desse BMU,e transformamos os nós em volta com atributos parecidos com o do BMU.
Sendo assim,nessa área do mapa vamos ter um padrão nos atributos. - Então quando for fazer o mesmo processo,e pegarmos um registro parecido com o primeiro registro,muito provavelmente ele vai cair na mesma área do mapa.
Dúvidas
– Só que minha dúvida é o seguinte professor,no link que eu li sobre o SOM,o N iterations vai ser o número de vezes que vamos pegar um registro e realizar todo esse passo a passo,só que como sabemos quantos clusters foram formados,e como eles são formados?
. por exemplo professor,eu assisti dnv as aulas,só que vamos supor que eu tenha uma base de dados considerável,e fazendo o calculo eu descobri que tem que usar um total de 120 neuronios,e nessa base de dados 100 neuronios foram selecionados como BMU,quer dizer que vamos ter 100 clusters?
-E Queria saber se esses calculos são feitos um registro de cada vez ou pegas varios registros aleatoria e calcula tudo de uma vez
mas todos são usados no treinamneto,ou a rede vai usar o mapa que se adaptou melhor ao problema?
O bias só e utilizado em problemas de regressão?
Por exemplo,tem 3 camdas de saída,ele vai retornar um valor entre 0 e 1.a camda que tiver o valor mais próximo de 1,vai ser a resposta final?(Usando Sigmoid)
então profesor,ela consegue fazer classificação com mais de duas classes?ja que só gera resultados entre 0 e 1?
-
AuthorPosts