
Naive-Bayes é um método de machine learning que usa as frequências das ocorrências em uma base de dados para prever uma variável de interesse. Seu nome vem do modelo estatístico bayesiano, que diz que o grau com que nós devemos acreditar numa afirmação vai ser ligeiramente alterado por novas evidências. Nós aplicamos o pensamento bayesiano cotidianamente sem nem mesmo saber. Imagine que você tenha a crença de que todos os gansos são brancos. Essa crença pode ser oriunda de sua experiência pessoal, pois todos os gansos que você viu são brancos, ou passada através de um conhecimento tradicional, quando foi seu pai quem lhe disse isso. Acontece que, um dia enquanto passeava pelo parque, você viu um ganso preto. Essa nova evidência deve alterar sua crença original: agora você deve acreditar que quase todos os gansos são brancos. Se no dia seguinte você encontrar mais dois gansos pretos, a crença é atualizada de novo: agora alguns gansos são pretos. O pensamento bayesiano é uma das formas fundamentais como formamos e atualizamos conhecimento.
O termo naive, que significa ingênuo em inglês, se deve ao fato de que o Naive Bayes não parte de um “grau de certeza” inicial; nós começamos a análise dos dados sem qualquer certeza a priori, e construímos esse grau analisando as frequências presentes nos dados que temos disponíveis.
O vídeo abaixo mostra um exemplo da aplicação do método de um ponto de vista mais matemático.
Dependendo da natureza dos dados com que estamos trabalhando, podemos aplicar diferentes tipos de Naive Bayes.
Gaussian Naive Bayes: é o método indicado para quando as variáveis independentes são contínuas e têm distribuição normal. Um exemplo seria tentar prever o risco de uma pessoa portar uma doença a partir de vários indicadores sanguíneos.
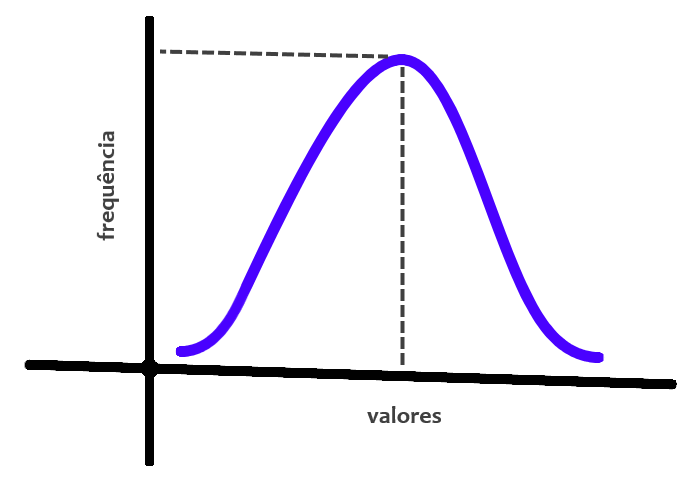
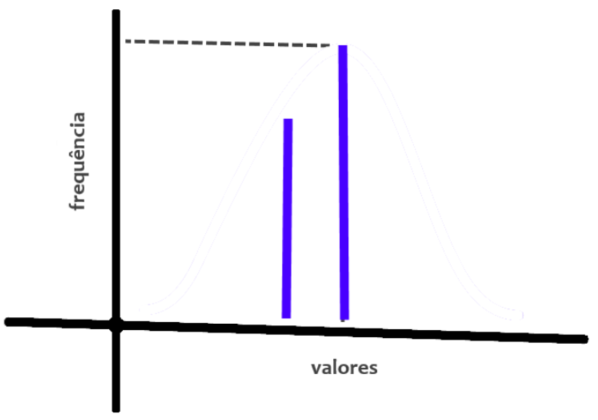
Bernoulli Naive Bayes: usado quando as variáveis independentes são discretas, mas apenas dois valores são possíveis, como os possíveis resultados de jogar uma moeda. Um exemplo seria tentar prever o grau com que uma pessoa vai gostar de um filme com base no seu sexo.
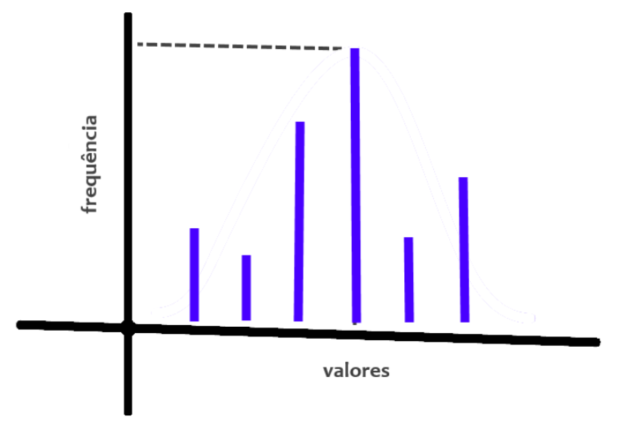
Multinominal Naive Bayes: as variáveis independentes também são discretas, mas agora são multinominais, o que significa que elas têm mais de um valor possível, como os possíveis resultados de uma jogada de dado. Pense em prever o grau de risco de crédito com base no estado civil das pessoas, que pode ter várias categorias: solteiro, casado, divorciado, viúvo.
Complement Naive Bayes: é um caso específico para problemas multinomais aplicado a bases de dados desbalanceadas, ou seja, quando as variáveis de saída têm probabilidades distintas. Suponha o exemplo acima do grau risco de crédito, sabendo que na sua base de dados a classe ‘risco alto’ aparece muito mais que a classe ‘risco baixo’.
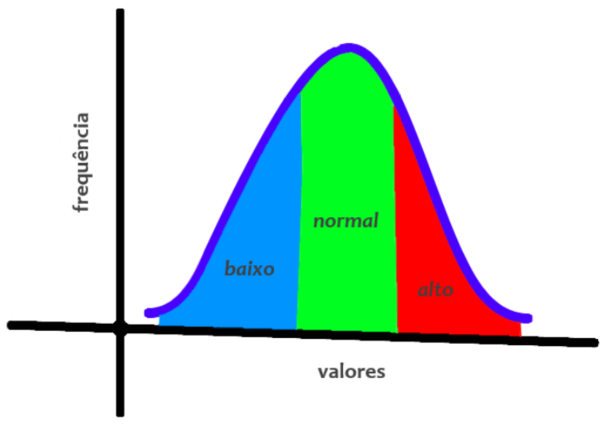
Dependendo da necessidade, é possível converter um problema do tipo Gaussian Naive Bayes em outro tipo, e assim alcançar um desempenho ainda melhor. Pense, por exemplo, em transformar a variável contínua níveis de colesterol em uma variável discreta contendo as categorias alto, normal ou baixo, obtidas a partir da transformação dos valores numéricos originais.
A biblioteca Scikit-Learn para Python possibilita a implementação desses quatro tipos de Naive Bayes. Além da natureza do problema a ser resolvido, o desempenho do modelo escolhido também vai depender dos parâmetros escolhidos para o treinamento, por isso o processo de tuning é fundamental.
Muito bom o material, parabéns pela dedicação a área de ciência de dados.
Valeu Jonathan! 🙂