
O trabalho de conversão de texto escrito em fala depende de duas tarefas. A primeira deve extrair o contexto das palavras, para decidir sutilezas como entonação. A segunda deve converter essa informação em som. Apesar de já existirem ferramentas com bom desempenho, até então o calcanhar de Aquiles dos algoritmos que convertem texto escrito em texto falado tem sido seu alto consumo de recursos: para atingir um resultado realista, onde a voz soe natural, é necessário um tempo elevado de treinamento e uma alta capacidade computacional. Mas um trabalho conjunto entre desenvolvedores da Microsoft e pesquisadores chineses acaba de ultrapassar essas limitações.
O sistema de inteligência artificial usa uma arquitetura de rede neural chamada de transformer, desenvolvida por uma equipe do Google em 2017. Até então, a extração de contexto de uma frase dependia de redes neurais recorrentes. As RNNs processam as palavras de forma sequencial, de forma que um trecho grande deve ser processado até que o contexto de cada palavra fique claro. Sua natureza sequencial torna o modelo inviável para paralelização, o que limita os ganhos de velocidade proporcionados pela utilização de TPUs e GPUs. O transformer, por sua vez, realiza um número pequeno constante de passos, onde aplica um mecanismo de “auto-atenção” para modelar diretamente as relações entre as palavras, independentemente de sua posição na frase.
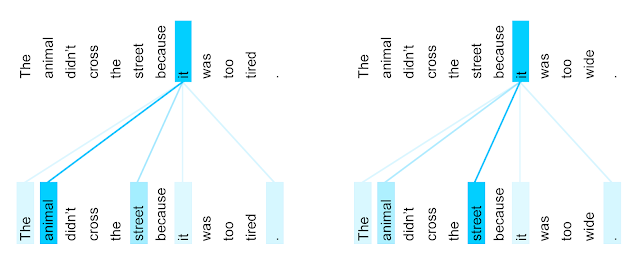
FRASE 2: O animal não cruzou a rua porque ela era muito larga.
O mecanismo de auto-atenção permite ao modelo entender que ‘it’ se refere a ‘animal’ no primeiro exemplo e a ‘street’ no segundo exemplo.
Essa abordagem lhe permite processar vários pequenos trechos em paralelo, o que resulta no processamento de entradas longas, como uma frase complexa, de forma eficiente. É como o cérebro humano funciona: nós vamos entendendo o sentido das frases conforme vamos ouvindo/lendo, e não apenas depois que elas finalizam um raciocínio. Essa característica, aliás, faz da arquitetura o melhor modelo disponível para a compreensão de linguagem.
Uma vez que o sentido da frase é captado, na segunda etapa do processo o sistema Text-to-Speech da Microsoft pode definir os padrões de estresse e intonação na linguagem falada, o que é chamado de prosódia. Ao invés de usar trechos de voz natural para montar o discurso, a abordagem usa a informação para agregar as unidades de fala em uma voz neural sintética.
Essas inovações processuais conjuntamente permitem que o sistema alcance o desempenho de 99,84% de inteligibilidade das palavras pronunciadas, usando apenas 20 minutos de texto falado para treinamento. Uma amostra em inglês de um discurso gerado através de um texto escrito de compreensão difícil pode ser ouvida abaixo.
TRADUÇÃO: “O terceiro tipo, um logaritmo de uma mudança de grandeza sem sinal, é sem dúvida o mais tratável.”
A economia de recursos tornada possível pela tecnologia faz com que o serviço de tradução text-to-speech se torne disponível para uma base maior de interessados, como desenvolvedores e pequenos negócios. Hospedada em um servidor, pode ser utilizada via streaming, oferecendo novas funções e personalidade a chatbots e assistentes virtuais, por exemplo. Aliás, esse é justamente o objetivo da Microsoft: a inteligência artificial já está disponível como API na plataforma Azure. No momento, o serviço usando vozes neurais, onde a naturalidade do discurso é próxima da perfeição, estão disponíveis em inglês, alemão, italiano e chinês.