
Uma rede neural funciona fazendo ajustes em seus parâmetros internos com base na diferença calculada entre os resultados por ela produzidos e os resultados conhecidos de um problema que se busca modelar. Acontece que existem várias formas de mensurar essa diferença (também chamada de erro do modelo), dependendo da natureza do problema. A função que realiza essa quantificação é chamada de função de custo, pois ela representa o custo, em termos de erro, de usar os parâmetros determinados em uma dada iteração, ou continuar treinando. Aliás, o objetivo do treinamento é definido matematicamente como minimizar o custo até um nível aceitável; para que essa função seja minimizada, os parâmetros da rede (pesos e biases) devem ser ajustados, já que os dados de entrada e os rótulos são constantes. Assim sendo, a escolha de uma função de custo adequada é essencial para que a rede neural convirja para a solução desejada.
De uma forma geral, a escolha da função de custo depende se o problema é de regressão ou de classificação, da natureza estatística dos dados, e da forma como o resultado é expresso. Nesse artigo, vou apresentar as principais funções de custo para problemas de regressão, e suas características.
1. Problemas de regressão
Problemas de regressão envolvem a predição de um valor numérico de natureza contínua. Por exemplo, prever o peso de uma pessoa em função de sua altura. Para esses casos, podemos considerar as seguintes funções de custo.
1.1 Erro quadrático médio (Mean squared error – MSE)
É uma das funções mais comuns, usada inclusive nos problemas de regressão linear, ou seja, quando se sabe que a relação entre os dados a serem preditos e os dados de entrada é estritamente linear. Essa função mede a diferença entre os resultados obtidos e o resultado real, eleva cada diferença ao quadrado, e depois calcula a média. Num exemplo usando três instâncias, seria isso:
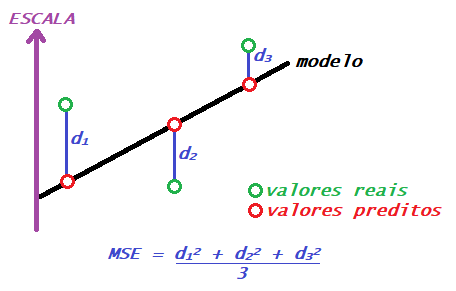
1.2 Erro absoluto médio (Mean absolute error – MAE)
A métrica anterior tem uma natureza quadrática, o que faz com que o erro aumente exponencialmente conforme aumenta a distância entre o valor predito e o valor real. Isso pode fazer com que o custo em um problema onde outliers são esperados seja penalizado excessivamente. Lembre, por exemplo, do problema de prever o peso de uma pessoa em função de sua altura: essa relação não é perfeitamente linear, já que nem todo centímetro a mais corresponde a uma quantidade exata de gramas. Nesses casos, uma solução melhor é o erro absoluto médio, que não penaliza de forma desigual os pontos mais distantes daqueles preditos pelo modelo. Para o exemplo acima, o cálculo seria:
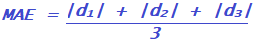
Dessa forma, imagine um modelo 1 que resulte em d1 = 4 e d2 = 0, e um modelo 2 que resulte em d1 = 2 e d2 = 2 . Pela métrica MSE, o segundo modelo é preferível, já que 42+ 02 = 16 (modelo 1) e 22+ 22 = 4 (modelo 2), mas pela métrica MAE, ambos os modelos são equivalentes, já que |4| + |0| = 4 (modelo 1) e |2| + |2| = 4 (modelo 2).
1.3 Erro percentual absoluto médio (Mean absolute percentage error – MAPE)
É usado quando a quantidade exata do erro não é importante, mas sim o percentual de diferença entre o valor predito e o valor real. O percentual é calculado em relação ao valor real.
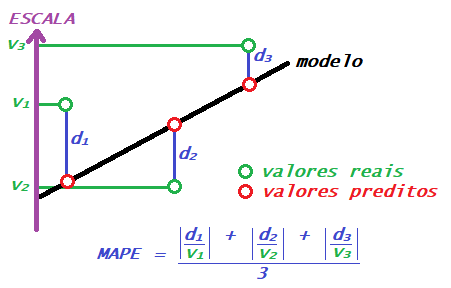
Assim sendo, os valores reais mais próximos de zero são mais penalizados, enquanto que os valores mais distantes são amortizados. Essa métrica é interessante quando os valores reais estão ao redor de zero e a presença de outliers é indesejada. Imagine por exemplo um exame laboratorial que seja calibrado para quantificar colesterol sanguíneo, mas que sua faixa de sensibilidade seja ao redor de um valor de referência; para valores muito distantes da referência, o método perde a sensibilidade. O modelo que busque traduzir os resultados do exame em níveis de colesterol (ou, no caso, em desvios da referência) seria melhor definido usando essa métrica, já que os valores mais distantes da referência não são relevantes.
1.4 Erro logarítmico quadrático médio (Mean squared logarithmic error – MSLE)
Assim como o MSE, o objetivo dessa métrica também é penalizar mais os erros maiores, mas não com tanta severidade. Para isso, ele primeiro determina o logaritmo dos valores reais e preditos, para depois operar como o MSE. Dessa forma, o valor das distâncias é reduzido consideravelmente, mas em caráter proporcional, e ainda assim as distâncias maiores são penalizadas mais.
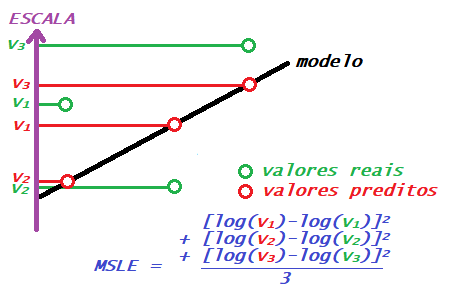
Essa métrica se adequa bem quando há razões para acreditar que desvios muito grandes do modelo devem ser considerados com cautela, mas são possíveis.
1.5 Proximidade de cosseno (Cosine proximity)
Essa métrica se baseia no ângulo formado entre dois vetores, onde cada vetor inicia na origem do sistema de coordenadas e termina nos valores reais e preditos. Abaixo, esse ângulo, denotado por α, está demonstrado apenas com os valores v3 do exemplo que temos usado. A equação para o cálculo dessa métrica é um pouco mais envolvida.
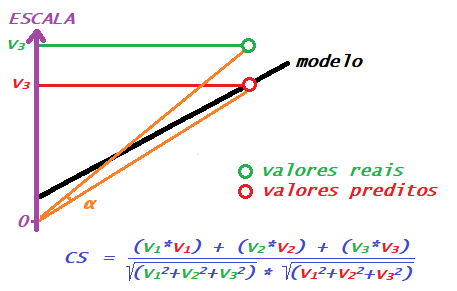
Pelo gráfico a gente observa que, quando mais próximos os valores reais e preditos, menor o ângulo entre os vetores, o que é traduzido em um menor erro calculado por essa métrica; quando mais distantes os valores, maior o ângulo e maior o erro. Essa é uma forma alternativa de penalizar os erros, baseada em conceitos de trigonometria.
Observações finais
No final das contas, se em dúvida, é possível fazer testes com todas essas métricas e observar o desempenho da precisão do modelo em função das épocas de treinamento. Se o erro começar a aumentar depois de aparentemente estabilizado, por exemplo, isso pode indicar que o modelo está sofrendo overfitting, e o problema pode ser na função de custo escolhida.

No próximo artigo, vou falar de métricas usadas para problemas de classificação.
Pingback: Fundamentos de ML: funções de custo para problemas de classificação (I) – IA Expert
Boa tarde, Denny!
Parabéns pelo conteúdo postado. Com ele foi possível esclarecer detalhes sobre a função para erro quadrático médio. Comecei a estudar DSA há pouco tempo e gostaria de “dicas” sobre livros para auxiliar meus estudos.
Valeu Denny!!!
Olá Ricardo, minha formação é mais baseada em cursos e desafios práticos, não conheço os melhores livros da área, mas é fácil encontrar sugestões na internet. Esta lista por exemplo parece bem interessante: https://hackr.io/blog/best-machine-learning-books
Parabéns pelo conteúdo.
Que bom que gostou, Adriana 🙂
Muito legal! Gostei muito da forma como você organizou e explicou as informações. Faço pós em ciência de dados e muito do que está aqui não consegui aprender em aula, mas pude entender bem melhor lendo da forma como você colocou.
Obrigado!
Que bom que gostou 🙂