
No artigo anterior, expliquei o que são funções de custo e mostrei os principais tipos para problemas de regressão. Agora, vou dar continuidade com as principais funções de custo para problemas de classificação. Nesse texto vou falar das duas mais comuns: entropia cruzada (cross-entropy) e hinge.
2 Problemas de classificação
São aqueles em que os dados de entrada servem para predizer a que classe cada instância pertence; por exemplo, numa análise de risco de crédito, os dados financeiros são usados para classificar as pessoas em alto, médio ou baixo risco. Os problemas de classificação podem ser de natureza binária, quando apenas duas classes são possíveis, ou de natureza multiclasse, quando existem mais do que duas classes. As funções de custo para esses problemas costumam levar essa natureza em consideração. Dependendo da métrica escolhida, as classes devem ser representadas de forma diferenciada, como será discutido em cada caso.
2.1 Entropia cruzada (Cross-entropy)
É considerada uma métrica clássica, sendo, via de regra, a primeira escolhida para resolver problemas de classificação. Entropia é um termo que tem origem na química, indicando quantidade de incerteza ou desorganização. Num problema de classificação, nós queremos dividir as instâncias em classes (ou grupos), onde cada grupo tem sua distribuição probabilística. Quando mais “bem definidos” esses grupos – mais concentrados e mais separados dos outros grupos – menor sua entropia.
No caso de um problema de classificação binária, é comum exprimirmos as classes com os valores 0 ou 1. Considerada essa notação, chamamos a probabilidade de pertencer ao grupo 1 de p, e a probabilidade de pertencer ao grupo 0 de seu complemento, 1-p. O cálculo da função de custo associada à entropia é:
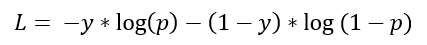
onde y é o valor real da instância.
Assim sendo, é possível calcular o custo associado ao resultado de predição de um modelo através do valor de p, que, como mencionado acima, indica a probabilidade de a instância pertencer ao grupo 1. Como p é uma probabilidade, ela deve estar expressa como qualquer valor entre 0 e 1, e por isso, no caso de redes neurais, é comum que problemas de classificação binária retornem valores finais depois de uma função sigmoide, que justamente converte qualquer valor da camada de saída para outro valor dentro da faixa [0, 1].
No caso de problemas de classificação multiclasse, o raciocínio é parecido, mas a fórmula é levemente alterada para comportar as demais classes. Para passar ao modelo, a coluna com as classes passa primeiro pelo processo chamado de one-hot encoding, onde cada classe vira uma nova coluna, e a instância que pertence a determinada classe recebe o valor 1 dentro daquela coluna, e 0 dentro das demais. Assim:

A fórmula é a seguinte:
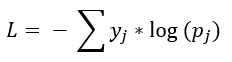
Agora, cada instância é avaliada para cada classe j. Observe que, se para yj = 1 (a classe verdadeira), pj também igual a 1 (ou seja, predição perfeita), então o resultado da função de custo é 0, que é exatamente o que se espera.
Como o modelo retorna um valor para cada classe, nesse caso é comum aplicarmos a função softmax antes de calcular o custo. Essa função transforma todos os valores para o intervalo [0, 1] ao mesmo tempo em que garante que a soma dos resultados seja igual a 1, o seja, a soma das probabilidades de uma instância pertencer a qualquer classe deve ser igual a 100%, o que indica que ela certamente pertence a alguma das classes.
2.2 Hinge
A função hinge foi desenvolvida primeiramente pra ser usada com Support Vector Machines (SVMs). No caso mais simples, as classes devem ser expressas com os valores -1 ou 1. Como o resultado do modelo também pode ser expresso nessa faixa, a função hinge tem condições de considerar se existe diferença de sinal entre a classe real e a classe predita. Multiplicando o valor real pelo predito, um resultado negativo indica uma previsão errada; um resultado positivo indica uma previsão correta.
No caso de classificação binária, a equação é:
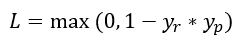
onde yr é o valor real e yp é o valor predito. Observe que yr só pode ser -1 ou 1, e yp pode ter qualquer valor entre esses dois extremos. Assim sendo, a multiplicação também fica restrita entre -1 e 1. Dessa forma, a segunda parte do operador max, 1 – yr * yp , pode resultar em qualquer valor entre 0 e 2, e o resultado da função de custo será esse valor ou 0, o que for maior. (Nesse caso, o operador max é até desnecessário já que a segunda parte da função nunca vai retornar um valor negativo, mas em aplicações mais amplas isso é possível, por isso a notação é mantida.) O custo será 0 se tanto yr quanto yp forem iguais a 1 e tiverem o mesmo sinal; o custo será máximo (igual a 2 no caso) quando ambos forem iguais a 1 mas de sinais diferentes. Essa é uma forma de penalizar não só o erro absoluto associado à predição, mas também se o resultado da própria classificação foi errado.
Como a função hinge exige valores expressos no intervalo [-1, 1], é comum passar os resultados do modelo pela função tangente hiperbólica (tanh) antes do cálculo do custo.
Para classificação multiclasse, a equação é levemente alterada:
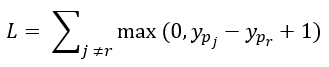
onde r indica a classe real e j indica as demais classes. Nesse caso, não se usa qualquer transformação nos resultados dos scores retornados pelo modelo, o que pode resultar em valores fora do intervalo [-1, 1]; além disso, a função de custo não depende de yr , o valor real da classe, apenas do valor de score de pertencer à classe real, retornado pelo modelo. Aí a segunda parte do operador max pode ter valores negativos – se o score retornado para a classe real for maior que o score para outra classe qualquer em pelo menos uma unidade -, e o operador garante que esse valor tenha o limite inferior de 0. Dessa forma, se o score dado à classe correta for maior do que o score para todas as demais classes em pelo menos uma unidade, o valor da função somatória é igual a 0, o que indica o menor custo possível. Se, pelo contrário, o score das demais classes for maior que o score da classe correta, a função tem seu valor máximo, o que indica o maior custo.
No próximo texto tratarei das principais funções de custo para problemas de classificação remanescentes.
Muito bem escrito, mas cadê a parte II? =(
Que bom que gostou, Jéssica! Por hora tem somente a parte 1 mesmo 🙁