
As redes neurais convolucionais foram inicialmente desenvolvidas para analisar imagens. A ideia básica dessa abordagem é aplicar filtros à imagem original para extrair propriedades visuais que podem ser usadas para classificar essas imagens. Em termos técnicos, estes filtros são matrizes numéricas usadas para acentuar as características visuais de uma pequena área da imagem original; os valores da matriz são multiplicados pelos valores correspondentes dos pixels selecionados da imagem, e depois somados para gerar um “resumo” da informação contida naquela área. Os filtros são aplicados à imagem inteira, deslizando através dela pelas dimensões de largura e altura, em cada um dos canais de cor. O resultado de uma camada convolucional pode passar por outras convoluções para extrair informações de um nível “mais elevado”. Podemos demonstrar esse conceito pensando que, em fotografias de pessoas, a primeira convolução reconhece bordas e contornos, a segunda reconhece os olhos, boca e nariz (formados pelas bordas e contornos), e a terceira reconhece rostos. Para uma compreensão mais detalhada do funcionamento de redes neurais convolucionais, disponibilizamos o vídeo:
A tarefa de entender textos é de uma natureza diferente porque, enquanto que uma imagem apresenta toda sua informação de uma vez só, textos têm uma propriedade temporal, que faz com que eles ganhem sentido na medida em que vão sendo produzidos/lidos. Por isso, via de regra, textos costumam ser processados por redes neurais recorrentes, cujas duas propriedades principais são: a capacidade de processar informações sequencialmente (por exemplo, uma palavra por vez), e a propriedade de manter uma memória, que ajuda a rede a compreender o contexto do texto já que, nem sempre, duas palavras relacionadas estão próximas uma da outra. Para maiores detalhes, favor ver o vídeo:
Só que essa forma de processamento apresenta como principal desvantagem sua velocidade. Como o texto é processado sequencialmente (ou seja, a segunda palavra só pode entrar na rede depois que a primeira palavra já passou por ela), não é possível paralelizar as operações, o que faz com que as redes neurais recorrentes sejam relativamente lentas.
Apesar do alto desempenho das redes neurais recorrentes para processar texto, algumas tarefas não precisam dessa estrutura. Em específico, a classificação de textos pode ser realizada não pelo contexto apreendido através da dimensão temporal, mas sim através da inspeção dos padrões regionais contidos em dimensões semânticas, de uma forma análoga ao processamento de imagens descrito acima (padrões regionais contidos em dimensões de cor). Com algumas adaptações, as redes neurais convolucionais podem ser usadas para classificação de textos em diferentes categorias.
Esta abordagem funciona porque textos podem ser apresentados ao algoritmo no mesmo formato que imagens, ou seja, em arrays numéricos com três dimensões. Para exemplificar, vamos trabalhar com a frase:
Eu tenho um gato e um cachorro.
A forma mais básica de transformar um texto em uma matriz é realizando o processo de one-hot encoding, onde cada palavra recebe sua própria dimensão. Assim, poderíamos representar esta frase da seguinte forma:
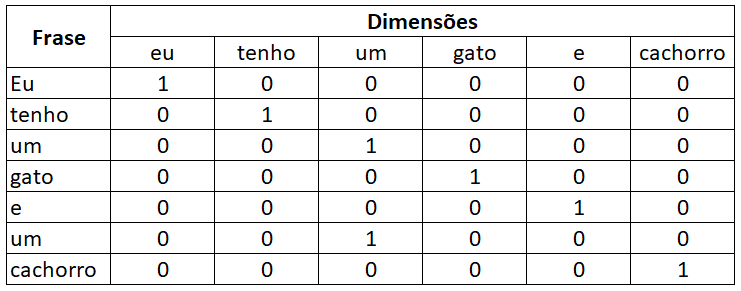
Observe que cada palavra se transforma um vetor cujo comprimento é igual ao número de palavras distintas na frase, e cujos valores são iguais a 0, menos na dimensão correspondente à palavra, onde é igual a 1.
A desvantagem de usar one-hot encoding é que todas as dimensões são independentes entre si, o que dificulta aplicar qualquer algoritmo que se baseie nas relações entre elas para realizar predições. Por isso, textos costumam ser representados como embeddings, que são vetores onde cada dimensão representa um espaço semântico contínuo. Neste caso, o número de dimensões é menor que o número de palavras distintas no texto. Para um entendimento melhor do método, sugerimos seguir esse link.
Após a transformação da frase do nosso exemplo em um embedding com 4 dimensões, poderíamos chegar a uma matriz como essa (os valores são fictícios):
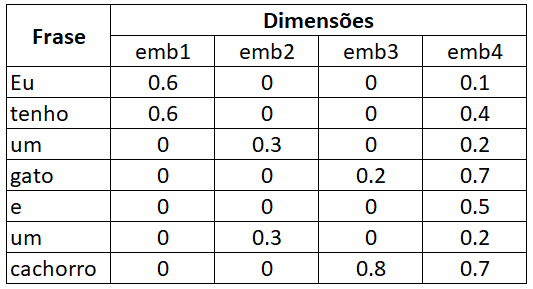
Geralmente, as dimensões dos embeddings são difíceis de interpretar, mas nesse caso eu usei valores para que emb1 representasse as 6 pessoas verbais (eu/tu/ele/nós/vós/eles), emb2 as variações dos artigos indefinidos (um/uma/uns/umas), emb3 animais de estimação, e emb4 a classe morfológica da palavra (pronome/substantivo/verbo/artigo/preposição…). Observe, por exemplo, que tanto as palavras eu quanto tenho se referem à primeira pessoa do singular, por isso têm o mesmo valor em emb1, mas são de classes morfológicas distintas, por isso têm valores diferentes em emb4. Observe também que algumas palavras não têm a propriedade representada por aquela dimensão, por isso o valor é 0; na prática, é bem difícil encontrar um valor com embedding igual à 0, já que as dimensões são geradas pelo algoritmo e não têm um significado real.
A partir daqui, nós podemos aplicar a ideia de convolução. Para isso, nós representamos a frase como se fosse uma imagem de largura igual ao comprimento da frase, altura igual a 1, e número de canais de cor igual ao número de dimensões de embedding. Ou seja, se uma imagem tem, por exemplo, dimensão 224x224x3, a frase acima tem dimensão 7x1x4. Agora é possível entregar o texto para uma rede neural convolucional, que funciona da mesma forma que para imagens, exceto que ela opera através de uma única dimensão, e não das dimensões largura e altura que existem nas imagens. O tamanho do filtro pode ser ajustado do mesmo jeito, representando o tamanho da janela que será processada a cada passo. Abaixo está exemplificada a aplicação de um filtro de tamanho 3 através da dimensão emb4:
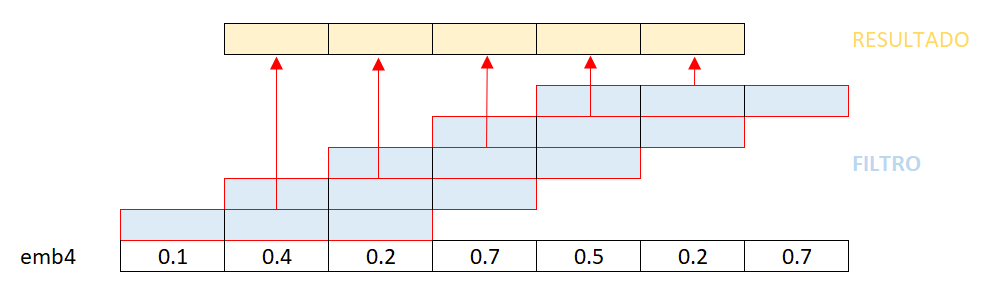
Assim como no caso das imagens, os resultados gerados pela aplicação de diferentes camadas convolucionais podem ser usados numa estrutura final densa para classificar textos.
Duas são as principais vantagens de usar redes neurais convolucionais com textos. A primeira é que, assim como no caso de imagens, a rede consegue ver o texto inteiro de uma vez, e não apenas os trechos contidos na janela selecionada como ocorre com as redes neurais recorrentes. A segunda é que, como o deslizamento do filtro ao longo do texto não depende de operações anteriores, essa etapa pode ser paralelizada, aumentando consideravelmente o tempo de processamento.
Esta aplicação demonstra a versatilidade das arquiteturas das redes neurais. Conhecendo seu funcionamento básico e a natureza do problema a resolver, não ficamos confinados aos casos para os quais elas foram inicialmente desenvolvidas, podendo estender para domínios que a princípio têm pouca relação entre si.
Olá. Muito interessante.
Tens um exemplo da estrutura desse modelo com keras?
Olá Leonardo. Não tenho nenhuma estrutura pronta, mas não me parece difícil montar uma rede sequencial cuja primeira camada é de embedding, a segunda convolucional e a terceira uma camada densa para classificação. Um abraço!