
Definição e características
As redes neurais são estruturas que promovem transformações matemáticas nos dados que recebem para processar. Em cada neurônio de cada camada, elas multiplicam o valor de entrada pelo peso do neurônio correspondente, somam com o bias associado ao neurônio, e passam esse valor adiante.
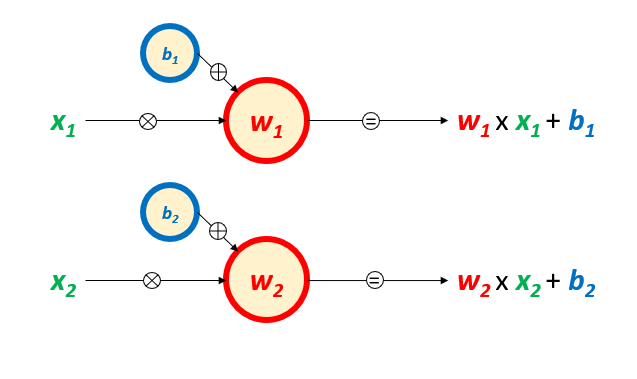
Acontece que essas operações são lineares, de forma que, por mais complexa que seja a rede neural, ela só pode captar relações lineares entre as variáveis de entrada e a variável de saída. Para torná-las capazes de modelar também relações não-lineares, os resultados de saída de cada camada passaram a ser processados pelas chamadas funções de ativação.
A principal razão pelas quais as funções de ativação são utilizadas, portanto, é para conferir essa capacidade não-linear ao processamento realizado pelas redes neurais. Isso é especialmente importante nas camadas escondidas da rede neural. Nas camadas de saída, as funções de ativação podem ter finalidades específicas, dependendo do problema que a rede neural está tentando resolver. Vou chamar a atenção para esses casos quando estiver discriminando os tipos de função de ativação, a seguir.
Quando aplicadas para conferir não-linearidade ao modelo, as funções de ativação devem ter idealmente algumas características:
- Custo computacional: É bom lembrar que operações matemáticas lineares são computacionalmente baratas. Portanto, uma função de ativação deve incrementar esse custo apenas na medida em que confere a característica desejada. Isso é especialmente relevante já que muitas funções de ativação são elas mesmas não-lineares. Em redes neurais grandes que serão treinadas por muitas épocas, o custo computacional adicional pode ter um impacto a se considerar.
- Diferenciabilidade: Durante o treinamento das redes neurais, seus pesos e biases são ajustados pelo mecanismo de descida do gradiente, que exige que cada operação matemática realizada em cada camada tenha sua derivada calculada. Portanto, essas operações devem ser diferenciáveis. Sem cumprir esse requisito, uma função não pode ser usada para ativação em uma rede neural.
- Centradas em zero: Isso quer dizer que o universo de resultados que a função de ativação é capaz de produzir deve ter iguais probabilidades de ser positivo ou negativo. Isso se deve ao fato de que, no cálculo do gradiente, o resultado da função de ativação é utilizado para determinar o valor do gradiente das operações anteriores. Se esse resultado for apenas positivo ou apenas negativo (ou seja, não centrado em zero), o valor do gradiente também será sempre positivo ou negativo, e os ajustes nos pesos e biases seguirão sempre uma única direção. Isso pode fazer com que a rede neural tenha dificuldades para convergir.
- Não produzir platôs: Platôs são regiões do universo de resultados que tendem a ser constantes. Quando uma função tem regiões constantes, a derivada nessas regiões tende a zero, o que causa o problema chamado de vanishing gradient, ou seja, o gradiente tende a zero e a rede não é mais capaz de convergir.
Principais funções de ativação
Linear
A função linear apenas aplica um fator de multiplicação ao valor que recebe.
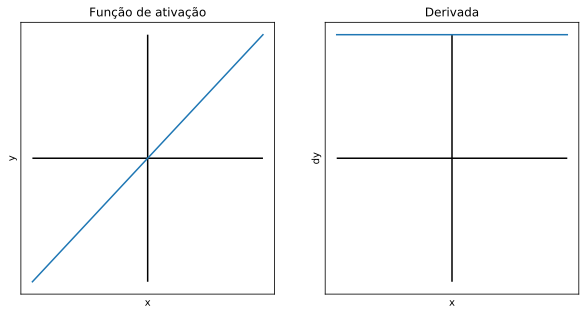
Apesar de cumprir todos os requisitos, essa função é limitada em sua capacidade de compreender relações mais complexas entre os dados, justamente por ser linear. Além disso, sua derivada é constante, o que faz com que o gradiente a cada etapa de back propagation seja constante, assim a etapa de descida do gradiente não tende a convergir para produzir um erro estável próximo de zero.
Na camada de saída, a função de ativação linear pode ser utilizada em problemas de regressão, já que produz resultados em todo o domínio dos números reais.
Sigmoide
A função logística ou sigmoide produz valores no intervalo [0, 1].
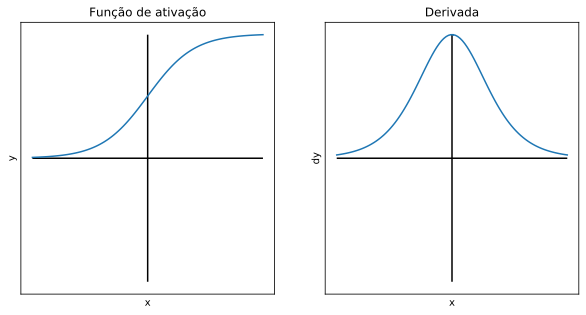
Ela é eficiente na questão da não-linearidade, e sua maior vantagem reside no fato de que o valor da derivada é máximo quando x está próximo de 0, o que tende a “empurrar” seu resultado para as extremidades do intervalo [0, 1] ao longo do treinamento, o que é uma característica desejável, por exemplo, em problemas de classificação. Entretanto, sua característica não-linear aumenta o custo computacional. Além disso, como se pode observar no gráfico, a função sigmoide não é centrada em zero. Ainda, ela apresenta platôs para valores de x muito altos ou muito baixos, o que faz com que a derivada nessas regiões se aproxime de zero. A soma dessas características não faz da função sigmoide uma boa opção para ativação das camadas escondidas.
Na camada de saída, a função sigmoide é útil para produzir probabilidades em problemas de classificação binária, já que seus resultados, na faixa de [0, 1], podem ser interpretados como a probabilidade de determinada instância pertencer ou não a determinada classe.
Softmax
Softmax é uma generalização da função sigmoide para casos não-binários. Ela não costuma ser aplicada às camadas escondidas da rede neural, mas sim na camada de saída de problemas de classificação multiclasse, já que sua característica é produzir valores no intervalo [0, 1] onde sua soma é igual a 1. Ou seja, num problema com 3 classes, por exemplo, a função softmax vai produzir 3 valores, que somam 1, onde cada valor representa a probabilidade da instância pertencer a uma das 3 possíveis classes.
Tangente hiperbólica (tanh)
Produz resultados no intervalo [-1, 1].
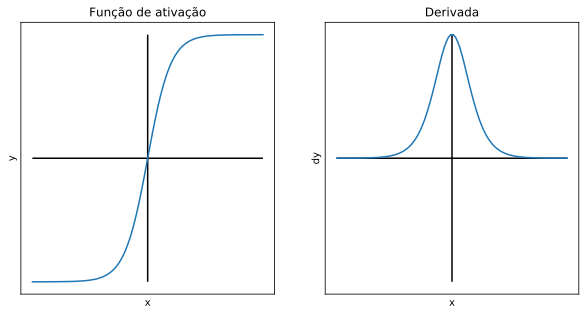
A tangente hiperbólica tem as mesmas vantagens e ainda resolve um dos problemas da função sigmoide, sendo centrada em zero. Entretanto, sua derivada também converge a zero, e mais rapidamente.
ReLU
ReLU é uma abreviação para rectified linear unit, ou unidade linear retificada. Ela produz resultados no intervalo [0, ∞[.
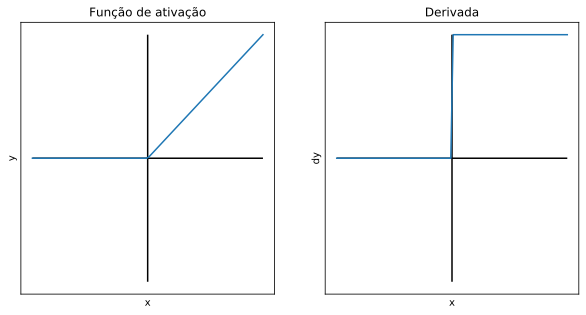
A função ReLU retorna 0 para todos os valores negativos, e o próprio valor para valores positivos. É uma função computacionalmente leve, entretanto não é centrada em zero. Como seu resultado é zero para valores negativos, ela tende a “apagar” alguns neurônios durante um passo forward, o que aumenta a velocidade do treinamento, mas por outro pode fazer com que esses neurônios “morram” e não aprendam nada se eles só receberem valores negativos. Além disso, ela pode produzir ativações explodidas, já que não possui um limite positivo. Mesmo com suas limitações, a função ReLU é hoje uma das funções de ativação mais utilizadas no treinamento de redes neurais, e não costuma ser utilizada na camada de saída.
Leaky ReLU
Esta é uma modificação da função ReLU, que ao invés de zerar os valores negativos, aplica a eles um fator de divisão (ajustado pelo desenvolvedor), tornando-os ao invés muito pequenos (próximos de zero). Leaky significa “vazando”, que é a ideia por trás dessa função. Esse comportamento tende a resolver alguns dos problemas da função ReLU relacionados aos valores zerados.
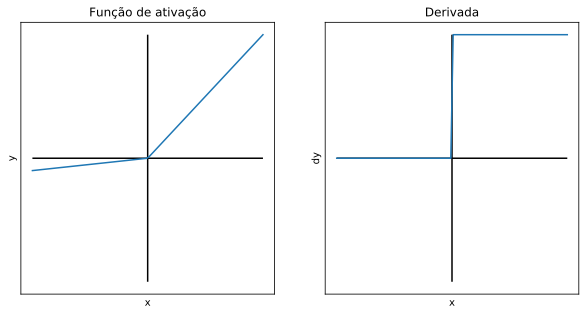
A função leaky ReLU costuma ter as mesmas vantagens que a função ReLU, e é aplicada quando a rede ativada com ReLU está tendo dificuldade para convergir.
Qual função usar?
Atualmente, dado seu desempenho, a função de ativação mais utilizada nas camadas escondidas é a ReLU, tendo a preferência na abordagem inicial do problema. Quando ela não é eficiente, pode-se recorrer às outras funções, considerando-se caso a caso.
Para as camadas de saída, podemos usar as recomendações dadas na descrição das funções, conforme a natureza do problema a ser resolvido. Em resumo, para problemas de classificação binária, podemos recorrer à função sigmoide, com a tangente hiperbólica também sendo uma possível solução; para classificação não-binária, podemos aplicar a função softmax; e para problemas de regressão, usamos a ativação linear.
Com este artigo, cobrimos as principais características das funções de ativação e os cenários onde cada uma pode ser aplicada.
Muito bom artigo! Explica bem cada função com prós e contras e dá um direcionamento de como usá-las.
Que bom que gostou 🙂
Artigo de leitura necessária, esclarecedor e com texto conciso proporcionando fácil entendimento,algo extremamente necessário para progresso no aprendizado em IA agradeço.
Olá, eu posso utilizar algumas imagens do conteúdo para eu colocar no meu trabalho, como eu poderia referenciar?
Olá Felipe, pode usar. Essas figuras são matemática básica, então não é necessário citar, mas se você quiser, pode seguir as recomendações aqui: https://www.todamateria.com.br/referencia-site-abnt/