
O primeiro grande salto de qualidade nos algoritmos de Processamento de Linguagem Natural aconteceu quando eles passaram a utilizar redes neurais recorrentes e suas derivações. Estas estruturas foram desenvolvidas para analisar séries temporais, ou seja, dados que têm uma característica que muda com o tempo. A linguagem pode ser considerada como dependente do tempo, já que as ideias que queremos expressar vão ganhando contexto conforme palavras são adicionadas ao texto, de forma ordenada.
O calcanhar de Aquiles das redes neurais recorrentes é que, como as etapas de processamento no tempo t dependem do processamento no tempo t-1, elas implementam computação sequencial, o que impede sua paralelização e todos os ganhos de velocidade que advêm disso. Este problema foi resolvido com o desenvolvimento dos transformers. Os transformers são uma implementação dos mecanismos de atenção, um conceito pelo qual cada token (que é uma abstração para palavras utilizada na área) é relacionado a todos os outros tokens da sequência que está sendo processada ao mesmo tempo, sem a necessidade de processamento sequencial. É desta forma que este mecanismo permite que o algoritmo aprenda as palavras que mantêm relação dentro da sequência, e assim construa o contexto do texto.
Um dos modelos mais bem sucedidos na implementação dos mecanismos de atenção em tarefas de PLN é o BERT, publicado pelo Google em 2018 e que hoje é o motor por trás do mecanismo de busca online que é o coração da empresa. Por permitir treinamento em regime paralelizado, o modelo pode utilizar os aceleradores de hardware mais modernos como GPUs e TPUs, o que torna possível treiná-lo com datasets muito maiores. Além disso, o BERT tem como característica determinar o contexto de maneira bidirecional, ou seja, tanto na ordem natural de leitura quanto na ordem reversa. Isto se mostrou extremamente benéfico nas tarefas de PLN, fazendo com que o modelo quebrasse vários recordes de desempenho nos desafios públicos que servem como parâmetro na área, relacionados por exemplo a tarefas de tradução, sumarização, geração de texto ou produção de embeddings para análise de sentimento.
Mas o BERT também possui suas limitações. A estrutura matemática do transformer faz com que o tempo computacional tenha uma relação quadrática com o tamanho das sequências que são analisadas, o que atualmente, mesmo com equipamentos robustos, tem limitado sua aplicação para sequências de no máximo 512 tokens. Isto é insuficiente para tarefas baseadas em textos mais longos, como por exemplo a sumarização de livros inteiros ou tarefas do tipo Q&A mais complexas, que devam consultar um corpus mais extenso.
Eis que ano passado o próprio Google apresentou uma evolução do conceito, que deu origem ao BigBird, um modelo capaz de processar sequências até 8 vezes mais longas que seu antecessor.
O BigBird resolve o problema da dependência quadrática no tempo computacional implementando um conceito de mecanismo de atenção esparso, através do qual cada token não é pareado com todos os tokens da sequência, mas apenas com alguns, selecionados de forma sistemática. Com isto, a dependência passou a ser linear, aumentando consideravelmente a quantidade de tokens que podem ser analisados dada a limitação de memória.
Basicamente, o mecanismo de atenção esparso foi baseado em tentativas anteriores de aumentar o potencial de uso dos transformers. Uma delas é o uso de janelas deslizantes, pelo qual um texto longo é entregue ao modelo, mas ele é processado em janelas de tamanho menor. Outra questiona o uso de atenção total, propondo soluções esparsas pelas quais somente alguns tokens são pareados aleatoriamente, com uma fração selecionada para formar pares com todos os demais. Uma terceira sugere o uso de tokens globais, que têm por objetivo servir como “âncora” da região do texto onde se encontram, como se fossem um resumo do contexto presente naquela área. O BigBird é fruto da incorporação destas três ideias em um modelo coeso.
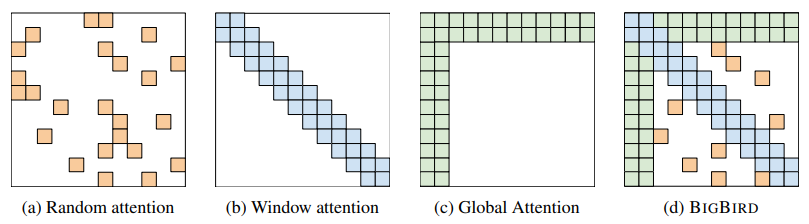
No trabalho publicado, os desenvolvedores do BigBird seguem a construção teórica do modelo com a demonstração prática de que os mecanismos de atenção esparsos podem ser considerados aproximações universais das funções do tipo sequência-para-sequência empregadas em mecanismos de atenção total, produzindo resultados similares em tarefas adequadas aos dois tipos de modelos, mas além disso, se sobressaem em tarefas que dependem de textos mais longos.
Na primeira avaliação, a modelagem da língua mascarada, alguns tokens do texto são removidos, e a tarefa é predizer qual é o token original. Basicamente, é como se o modelo tivesse que adivinhar qual é a palavra faltante, baseada somente no contexto. Com quatro dos datasets analisados, o BigBird se revelou o novo estado da arte, o que reforça a ideia de que textos mais longos são mais úteis na construção de contexto.
Em tarefas do tipo Q&A com respostas longas, o BigBird também é o novo líder em três dos quatro datasets considerados.
Em tarefas de classificação de documentos, o BigBird chegou a superar o antigo líder em 5% em um dos cinco datasets, tendo desempenho comparável aos outros modelos nos demais.
Em tarefas de sumarização de documentos longos, o BigBird é o novo padrão de comparação para os três datasets analisados.
O trabalho ainda se preocupou em testar as capacidades do BigBird frente a um tipo bem diferente de linguagem, aquela expressa pelo DNA. Modelos de PLN têm sido empregados na área da genômica com certo sucesso, já que a informação contida nas bases simples do DNA não deixa de ser algo que ganha contexto quando transformada em função biológica. Neste caso, modelos capazes de inferir contexto com base em sequências longas são tecnicamente mais apropriados, já que as informações relevantes no DNA podem estar bastante distantes. O BigBird desempenhou muito bem também nesta avaliação, superando seus concorrentes em três tarefas: modelagem de linguagem mascarada, predição de região promotora (que é uma região anterior a um gene onde de fato a atividade genética inicia) – onde inclusive o modelo atingiu precisão de 99,9% -, e predição de perfil da cromatina (que trata de funções do DNA em regiões que não codificam proteínas, e que costumam estar associadas a doenças de causa genética).
Os resultados alcançados pelo BigBird permitem duas conclusões interessantes. Primeiro, o mecanismo de atenção total não é necessário, o que implica em economia de recursos. Segundo, sequências mais longas podem enriquecer o contexto de textos, o que melhora o desempenho de modelos em tarefas de PLN. Além disso, a publicação deste modelo apenas dois anos depois da estreia do BERT mostra que vivemos numa época empolgante onde a inteligência artificial tem dado saltos impressionantes de qualidade numa velocidade inédita.
Todo o código relacionado ao desenvolvimento do BigBird está disponível para acesso público no GitHub.