
Introdução
O Processamento de Linguagem Natural é uma das áreas da Inteligência Artificial que está em franco crescimento em termos de novas bibliotecas e novos modelos de Machine Learning e Deep Learning. Aplicações de Processamento de Linguagem Natural – PLN, ou em inglês, Natural Language Processing – NLP, possui diversas aplicações como detecção do tópico, identificação de termos sintáticos, chatbots, análise de sentimentos, dentre outros.
Neste ano, muito se publicou sobre as bibliotecas Bert e GPT-3, apresentando excelentes resultados. O surgimento de novidades não implica dizer que modelos tradicionais de Machine Learning não façam bom trabalho.
Durante o período de julho de 2019 a setembro de 2020, coletei resenhas de usuários de apps de bancos brasileiros postados Google Play. As resenhas se referiam aos apps principais (não considerei apps de versão light ou de funções específicas como cartões de crédito por exemplo) dos seguintes bancos: Banco do Brasil, Banco Itaú, Bradesco, Caixa Econômica Federal e Nubank. No total foram coletadas 10.073 resenhas. Essas resenhas foram armazenadas em planilha, ficando apartadas 8.698 resenhas em um conjunto de dados e outras 1.375 resenhas em outro conjunto de dados.
Cada resenha foi classificada em cinco interpretações não excludentes:
- elogio ao app;
- reclamação contra o app;
- elogio à instituição financeira;
- reclamação contra a instituição financeira;
- não classificável.
O objetivo foi de construir 2 classificadores. O primeiro deve prever se a resenha possui ou não uma crítica, seja ela em relação ao app ou em relação à instituição financeira. O segundo deve prever a classificação atribuída foi de 5 estrelas ou não.
O objetivo deixa claro que aqui será tratado de aprendizado supervisionado e de problema de classificação binária. O conjunto de dados com 8.698 registros foi utilizado para análise dos dados e geração do modelo de Machine Learning. O segundo conjunto foi utilizado para validação dos resultados obtidos.
Este trabalho não tem por objetivo apresentar o melhor app de instituição financeira. Isso fica evidenciada na ausência de técnicas de coleta de amostra dos dados.
Análise Exploratória dos Dados
O conhecimento dos dados que estamos tratando é importante para conhecer o tamanho do desafio com que estamos trabalhando. A melhor forma de fazer isso é visualmente, através de gráficos.
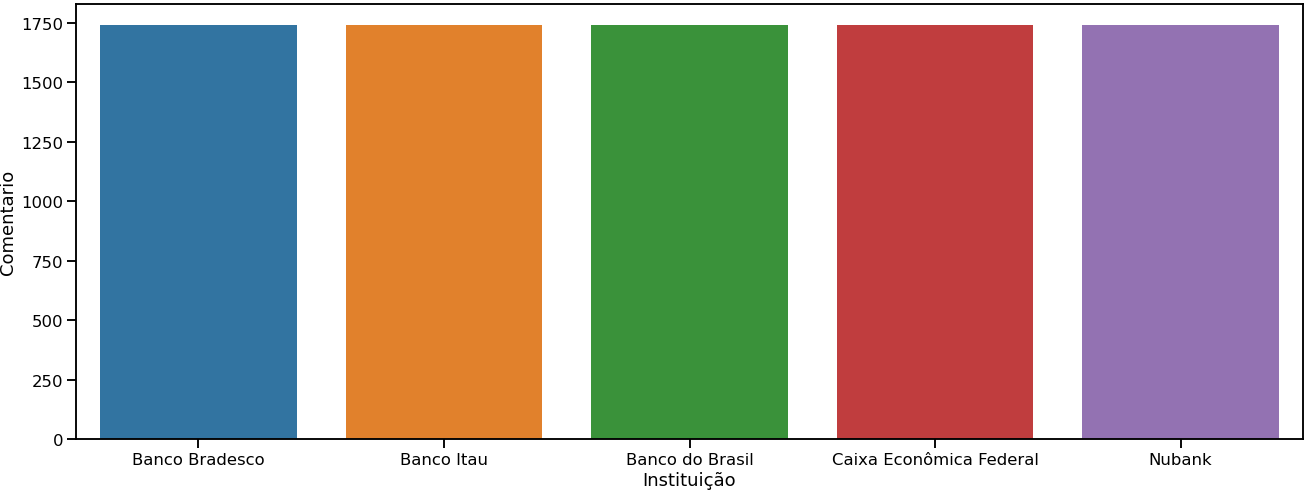
Primeiro, verifiquei que a quantidade de resenhas por instituição está balanceada, o que é comprovado pelo gráfico 1.
Gráfico 1: quantidade de resenhas por instituição financeira
A avaliação média de cada app por instituição financeira apresentou o resultado do gráfico 2.
Gráfico 2: classificação média por instituição financeira
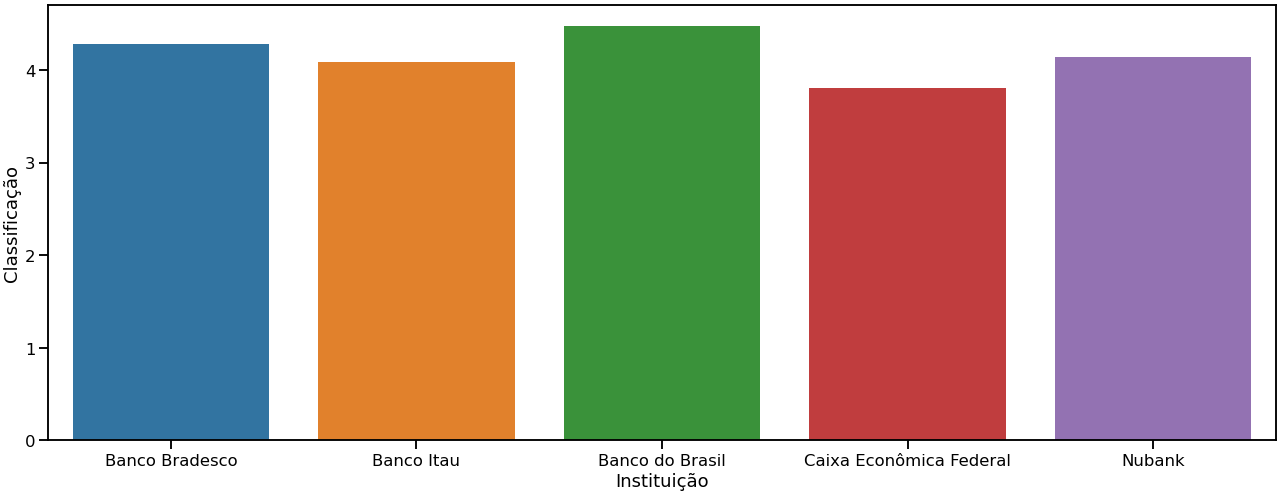
O gráfico 1 não traz nenhuma preocupação, já o segundo gráfico começa a apresentar um pequeno enviesamento favorecendo a maior presença de classificações altas.
O gráfico 3 corrobora com a informação acima. A predominância de classificações 5 estrelas é muito maior que as demais classificações, destacando a classificação 2 estrelas e 3 estrelas que são as que possuem a menor quantidade de classificação. O desbalanceamento das classes deve ser tratado quando da construção dos modelos de Machine Learning.
Gráfico 3 – quantidade de avaliação por classificação
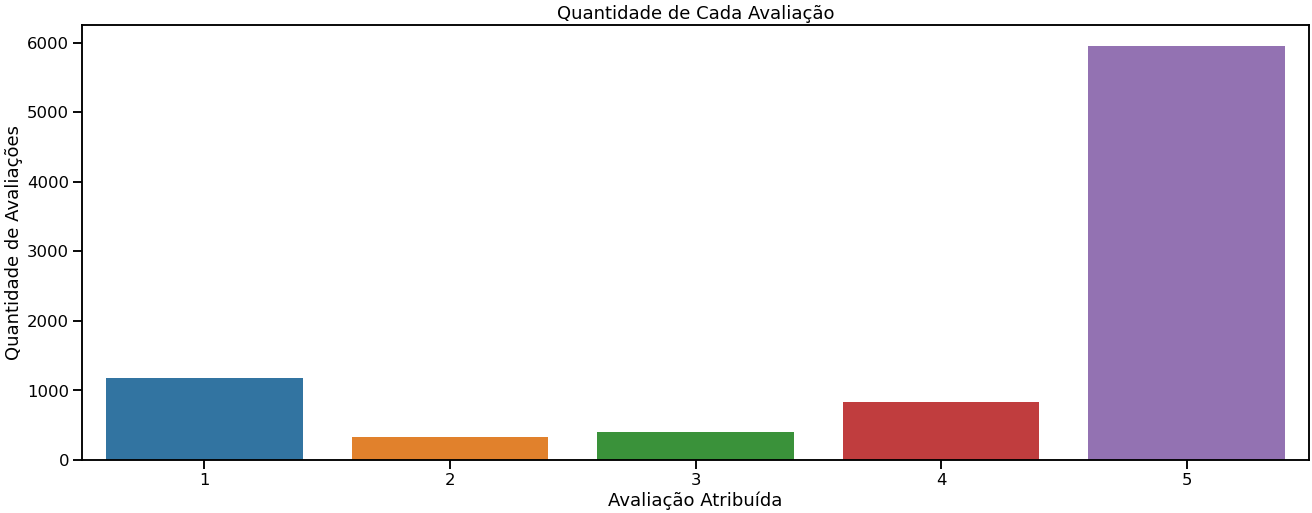
Alguns destaques quando se faz a mensuração do gráfico 3 segmentada por instituição financeira, foram:
- o app do Banco Itaú e da Caixa Econômica Federal não ultrapassaram o limite de 1200 classificações 5 estrelas, o gráficos 4 e 5 apresentam as classificações dos apps destas instituições;
- o app da Caixa Econômica Federal é o que possui maior quantidade de classificações 1 estrela (gráfico 5)
- o app do Banco do Brasil é o único em que a quantidade de classificações 1 estrela não ultrapassou o limite de 200 classificações e é o que possui maior quantidade de classificações 5 estrelas (gráfico 6).
Gráfico 4 – Classificações do app do Banco Itaú

Gráfico 5 – Classificações do app da Caixa Econômica Federal

Gráfico 6 – Classificações do app do Banco do Brasil

Outro destaque é em relação a evolução da média das classificações ao longo do tempo. O app da Caixa Econômica Federal apresentou um salto na quantidade de classificações 5 estrelas a partir da segunda quinzena de março de 2020, chegando quase a formar um platô a partir de então, como se observa no gráfico 7.
Gráfico 7 – Classificação média no tempo app Caixa Econômica Federal

A quantidade média de caracteres das resenhas dos apps segmentada por instituição financeira também é uma observação interessante. Todos apresentam picos em determinados períodos, como por exemplo no Gráfico 8 que é referente ao app do Bradesco. Esse comportamento é interessante também no app da Caixa Econômica Federal, pois, o gráfico 9 deixa bastante clara a redução da quantidade média de caracteres.
Gráfico 8 – Quantidade média caracteres no tempo app Bradesco

Gráfico 9 – Quantidade média caracteres no tempo app Caixa Econômica Federal

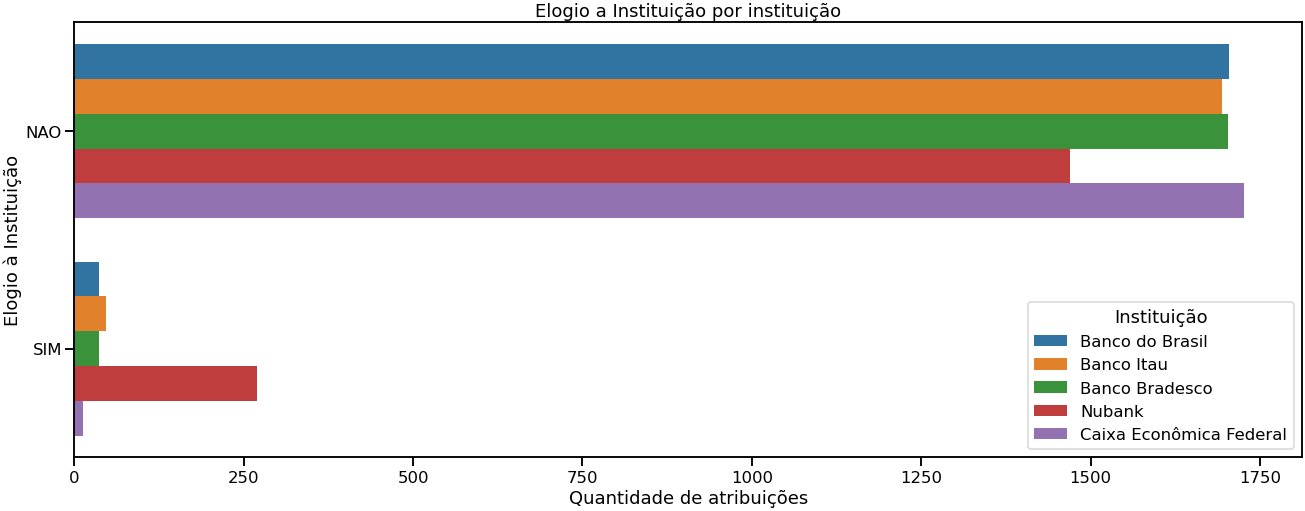
Em relação às interpretações das cinco categorias apresentadas na introdução, os gráficos 10 e 11 mostram que a quantidade de resenhas alusivas aos apps é muito maior do que a quantidade de resenhas destinadas a instituição financeira, exceto para o app do Nubank, que se destaca ao receber muitos elogios em relação a instituição Nubank.
Gráfico 10 – Quantidade de elogios aos apps por instituição financeira

Gráfico 11 – Quantidade de elogios às instituições por instituição financeira
Por fim, a maior parte das resenhas possuem poucas palavras. Abaixo, o gráfico 12 exibe a distribuição da quantidade de palavras.
Gráfico 12 – Distribuição da quantidade de palavras

Tratamento dos Dados
O tratamento dos dados variou em poucas partes, conforme o objeto do modelo de Machine Learning criado.
Para o modelo destinado a identificar críticas foi criada a variável “comentario_negativo”, com valores 0 e 1, onde 1 indica a presença de comentário crítico na resenha. Para o modelo destinado a identificar classificação igual a 5 estrelas, foi criada a variável “5_estrelas”, com valores 0 e 1, onde 1 indica que foi atribuída classificação 5 estrelas.
O tratamento dos dados iniciou com uso da biblioteca Emot. Por esta biblioteca é possível identificar emojis e emoticons em um texto e traduzi-los para seu sentido literal. Abaixo, a definição da função para localizar os emojis e emoticons:
def localiza_emoji_emoti(texto):
emoji = emot.emoji(texto)
emoti = emot.emoticons(texto)
if emoji['flag'] == True:
emojis.append(emoji['value'])
try:
if emoti['flag'] == True:
emotis.append(emoti['value'])
except:
emotis.append('nada')
Consegui identificar 105 emojis e 5 emoticons. Momento em que criei um dicionário para traduzir se o emoji ou emoticon fazia alusão a um elogio ou a uma crítica. Então foi criado um dicionário para manipular os emojis e emoticons, onde eles foram traduzidos para as palavras ótimo ou ruim.
Ao trabalhar com Processamento de Linguagem Natural é comum tratar as chamadas stopwords. As stopwords são palavras que não atribuem significado ao texto. Como apresentado na análise exploratória dos dados, a presença de resenhas com poucas palavras é significativa, explicitado no gráfico 12, assim, procurei identificar resenhas que possuem apenas uma palavra e as palavras classificadas como stopwords, foram removidas da lista de stopwords.
A biblioteca Spacy possui 413 palavras da língua portuguesa classificadas como stopwords. Após o processamento indicado no parágrafo anterior, a lista de stopwords deste trabalho ficou com 409 palavras.
Outro aspecto comum ao trabalhar com Processamento de Linguagem Natural é reduzir a palavra a sua forma bruta, chamado de lematização. Um exemplo explica melhor: palavras como “bom”, “melhor” e “ótimo” são transformadas em “bom” ao aplicar a lematização.
A eliminação de stopwords e a aplicação da lematização são etapas importantes no Processamento de Linguagem Natural porque diminuem significativamente o tamanho do vocabulário.
Por fim, foi criada uma função para processamento de todo o texto com as seguintes etapas:
- converte o texto para minúsculas;
- substitui os emojis e emoticons pelas palavras ótimo ou ruim;
- aplica a lematização;
- remove stopwords e pontuações;
- remove números e excesso de espaços em branco.
Abaixo, a função de processamento de texto final:
def preprocessamento(texto):
# Letras minúsculas
texto = str(texto).lower()
# converter emoji/emoticon para texto
texto = traduzir_emoti_emoji(texto)
# Espaços em branco
texto = re.sub(r" +", ' ', texto)
# Lematização
documento = pln(texto)
lista = []
for token in documento:
lista.append(token.lemma_)
# Stop words, pontuações e espaços em excesso (função strip)
lista = [palavra for palavra in lista if palavra not in ls_stop_words and palavra not in pontuacoes]
lista = ' '.join([str(elemento) for elemento in lista if not elemento.isdigit()]).strip()
return lista
Na etapa de Feature Engineering, foram criadas 25 novas variáveis. Essas variáveis dizem respeito a quantidade de caracteres, e palavras, de substantivos, de verbos, também dizem respeito a proporção de verbos, substantivos, adjetivos etc em relação a quantidade de palavras e de caracteres. A identificação de aspectos do texto como substantivos, verbos, advérbios dentre outros se deu através do uso do processamento de cada resenha via Spacy. Os detalhes podem ser consultados no repositório, mas, abaixo apresento graficamente a identificação do que é chamada parte do discurso, ou, part of speech para o seguinte texto:
Muito útil e eficiente, esse App! Parabéns Banco do Brasil!!!!👍👍👍

O Spacy também possui a capacidade de identificar as dependências entre os termos:

Concluído o tratamento dos dados, foi construído o vetorizados. Para os dois classificadores, o vetorizador construído foi o TFIDF, sigla para Term Frequency Inverse Document Frequency.
O vetorizador TFIDF atribui uma importância a cada palavra tendo como resultado o produto da sua frequência na resenha pelo inverso da sua presença nos documentos.
A frequência do termo (term frequency) diz respeito a quantidade de vezes que o termo ocorre em um documento. Quanto mais frequente maior o TF. Se a mesma palavra ocorre muitas vezes em um documento e também ao longo de outros documentos, a ela é atribuído um baixo valor de IDF.
Assim, no TFIDF, o resultado é que palavras constantes ao longo de documentos recebem valor menor por trazer menor significância em termos de interpretação.
Tanto para o vetorizador para o modelo que identifica a presença de críticas quanto para o vetorizador para o modelo identifica se a classificação é 5 estrelas, foi criado para analisar unigramas e bigramas. O primeiro vetorizador foi criado com as 300 variáveis mais significativas e o segundo com as 600 variáveis mais significativas.
Além da abordagem do TFIDF para criação de vetorizadores, há a abordagem do saco de palavras, ou bag of words. Sua implementação é a mesma do TFIDF. O saco de palavras considera a frequência do termo e sua presença no documento.
O leitor pode verificar o desempenho dos modelos com bag of words ao invés do TFIDF, bastando alterar a implementação dos vetorizadores. Os passos seguintes a criação do vetorizador serão os mesmos. A função no Scikit Learn é a CountVectorizer.
A vantagem de limitar a quantidade de variáveis geradas pelo vetorizador é evitar a ocorrência do overfitting. O overfitting ocorre quando o modelo de Machine Learning aprende demais sobre os dados de treinamento e se torna incapaz de generalizar sobre dados ainda não vistos. Isso é percebido ao se apurar os resultados, que é caracterizado por altíssima performance no conjunto de dados de treinamento e uma performance ruim nos dados de teste.
Os unigramas é a análise das palavras em sua forma única. Já o bigrama analisa as palavras na forma de duplas. Assim, para a resenha “O app é ótimo”, a análise em unigrama retornaria: “O” – “app” – “é” – “ótimo”. Já a análise em bigramas retornaria: “O app” – “app é” – “é ótimo”.
Abaixo, exemplo da criação do vetorizador:
vect = TfidfVectorizer(stop_words=ls_stop_words,
ngram_range=(1, 2),
max_features=300
).fit(resenhas_treino.coment_processado)
O vetorizador foi convertido para um Dataframe do Pandas, para facilitar que a ele fossem incluídas as variáveis criadas na etapa de Feature Enginering.
Construção dos Modelos
A construção dos modelos se inicia com a divisão dos dados em treino e teste. Aqui foi feita a proporção de 90% para o treinamento e 10% dos dados para testes.
Apesar de os conjuntos de dados estarem agrupados por datas e instituição financeira, ressalto que a função train_test_split do Scikit-Learn faz reordenamento dos dados por padrão.
Após a divisão dos dados em treino e teste, foi utilizada a biblioteca Imblearn, através da função Smote, para gerar dados sintéticos, permitindo que as classes ficassem balanceadas, aumentando a quantidade de dados.
Por fim, para manter os dados na mesma escala (normalização), foi feito uso da função Min Max Scaler do Scikit-Learn. Essa função é indicada para variáveis que não seguem a curva normal, a famosa curva de distribuição em forma de sino. Importante salientar que a normalização é criada sobre os dados de treinamento e aplicada sobre os dados de teste e de validação. Portanto, é fundamental sua aplicação somente após a divisão dos dados.
Para construção dos modelos foi feito uso da função Randomized Search CV. Gosto de utilizar esta função por que ela executa duas tarefas ao mesmo tempo: identifica os melhores hiperparâmetros e faz a validação cruzada. O Randomized Search CV foi aplicado nos modelos: Multinomial Naive Bayes, Logistic Regression, Random Forest Classifier e Gradient Boosting Classifier.
Sem o uso da função Randomized Search CV criei modelo de Deep Learning diretamente da biblioteca Spacy.
Para identificar a performance de cada modelo e selecionar o melhor, criei uma função que retorna a acurácia e o F1 Score, além dos gráficos de matriz de confusão e de curva ROC.
A acurácia é a proporção de predições corretas, sem levar em consideração o que é positivo e o que é negativo.
O F1 Score é uma combinação entre a precisão e o recall. Trata-se de uma média harmônica entre as duas métricas. A precisão é porcentagem de acertos sobre o total de predições realizadas para cada classe. O recall a porcentagem de acertos sobre o número total de instâncias existentes em cada classe.
A Curva ROC é similar ao gráfico precisão-recall, mas, suas dimensões são a taxa de verdadeiros positivos (recall) e a taxa de falso positivo.
Abaixo, exemplo de relatório emitido pela função usando o modelo de Deep Learning do Spacy:
======= RELATÓRIO DE DESEMPENHO =======
Apurado nos dados de treino
—————————
Acurácia: 98.9525%
F1 score: 98.95%
Apurado nos dados de teste
—————————-
Acurácia: 91.3793%
F1 score: 91.3975%
===== FIM RELATÓRIO DE DESEMPENHO =====
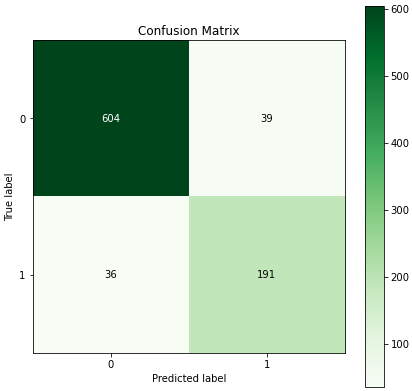
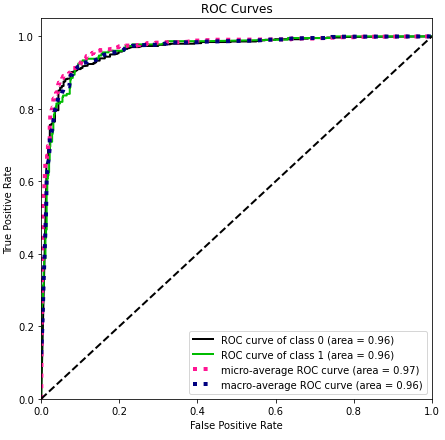
Os resultados obtidos sobre os dados de teste para os modelos que visam identificar a presença de críticas nos textos foram os seguintes:
| Modelo | Acurácia | F1 Score | Curva ROC |
| Multinomial Naive Bayes | 91,26 | 91,52 | 0,97 |
| Logistic Regression | 87,93 | 88,38 | 0,96 |
| Random Forest Classifier | 90,46 | 90,53 | 0,96 |
| Gradient Boosting Classifier | 92,41 | 92,44 | 0,96 |
| Deep Learning Spacy | 91,61 | 91,63 | 0,95 |
Os resultados obtidos sobre os dados de teste para os modelos que visam identificar classificação 5 estrelas foram os seguintes:
| Modelo | Acurácia | F1 Score | Curva ROC |
| Multinomial Naive Bayes | 86,21 | 86,19 | 0,91 |
| Logistic Regression | 84,83 | 84,99 | 0,9 |
| Random Forest Classifier | 81,72 | 84,61 | 0,9 |
| Gradient Boosting Classifier | 81,72 | 81,62 | 0,9 |
| Deep Learning Spacy | 83,1 | 82,99 | 0,87 |
Os resultados obtidos sobre os dados de validação com o modelo Gradient Boosting Classifier, para identificar a presença de críticas nos textos foram os seguintes:
| Modelo | Acurácia | F1 Score | Curva ROC |
| Gradient Boosting Classifier | 91,85 | 91,82 | 0,96 |
Os resultados obtidos sobre os dados de validação com o modelo Multinomial Naive Bayes, para identificar classificação 5 estrelas foram os seguintes:
| Modelo | Acurácia | F1 Score | Curva ROC |
| Multinomial Naive Bayes | 83,1 | 82,99 | 0,87 |
Conclusão
Este trabalho mostrou que é possível obter bons resultados com modelos tradicionais de Machine Learning.
Há outras formas de se iniciar um trabalho de Machine Learning, como por exemplo, iniciando de imediato a criação de modelos, permitindo assim verificar se o conhecimento dos dados e o tratamento dos dados melhora a capacidade do modelo.
Embora não se tenha uma regra específica de como fazer, é importante ter em mente que se deve conhecer e tratar os dados para depois criar os modelos de Machine Learning e Deep Learning. Isso fica evidente para os casos aqui tratados, uma vez que ambos apresentaram desbalanceamento de classes.
Onde este trabalho está
Kaggle com a Análise Exploratória dos Dados
Kaggle com a classificação quanto do texto
Kaggle com a classificação do app (quantidade de estrelas)
Referências
O que é Natural Language Processing, o tal do NLP — Data Hackers Podcast 27
A General Approach to Preprocessing Text Data
Emoticon and Emoji in Text Mining